AdRoll
On This Page
AdRoll is a tool used by marketers to show ads on various Social Media tools, such as, Facebook and Instagram, to people who are likely to click them, using real-time bidding. With AdRoll, marketers can add pricing strategies to setup retargeting, which enables them to remind their customers of products and services after they leave the website without buying, a feature which is not supported by platforms like Google Adwords.
AdRroll uses the concept of Advertisables, or advertiser profiles, that help you manage campaigns for multiple websites in a single AdRoll account. You can toggle between multiple Advertiser profiles and manage access and campaigns for each of these individually.
You can fetch reports related to users’ interaction within AdRoll, such as, reports about campaigns, ad groups, and conversions and replicate these to a database or data warehouse using Hevo Pipelines.
Prerequisites
-
An active AdRoll account from which data is to be ingested exists.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring AdRoll as a Source
Perform the following steps to configure AdRoll as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select AdRoll.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your AdRoll account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add AdRoll Account and perform the following steps to configure an account:
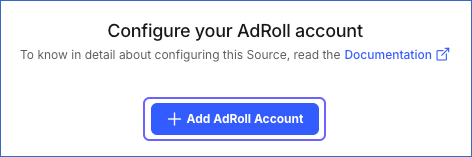
-
Log in to your AdRoll account.
-
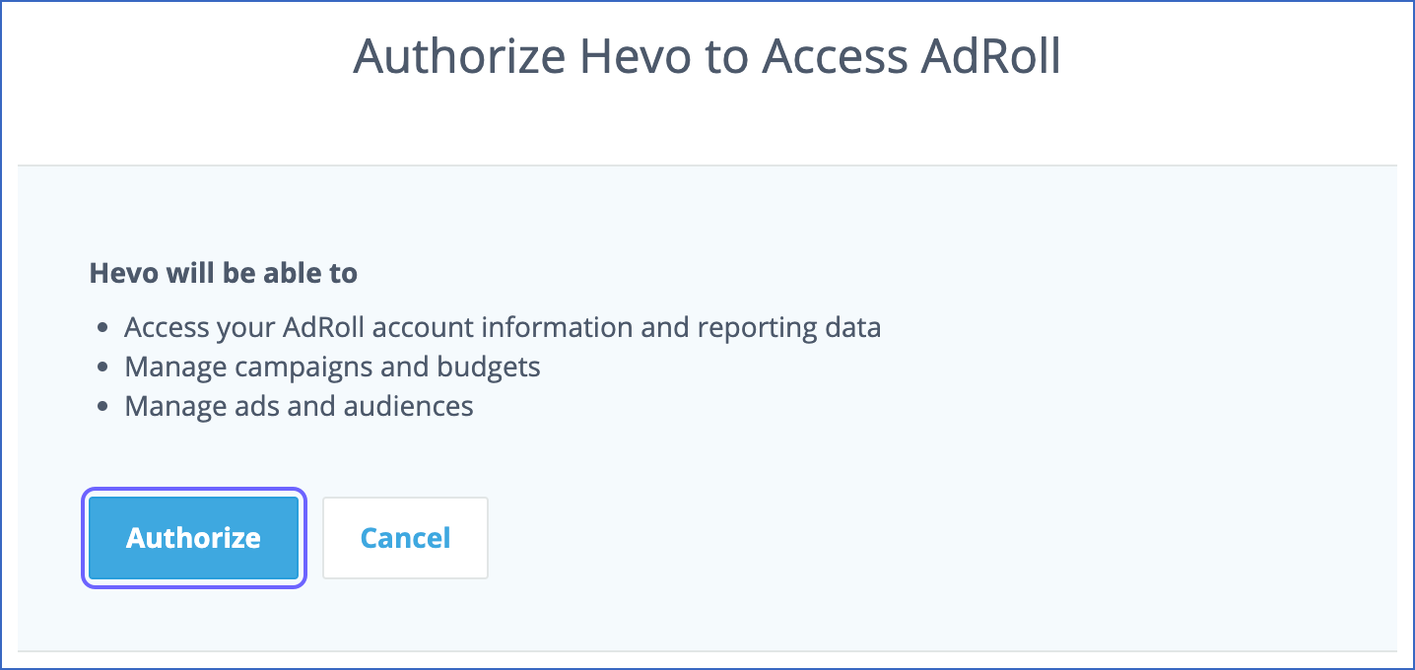
On the Authorize Hevo to Access AdRoll page, click Authorize. This allows Hevo to access your reporting data.
-
-
-
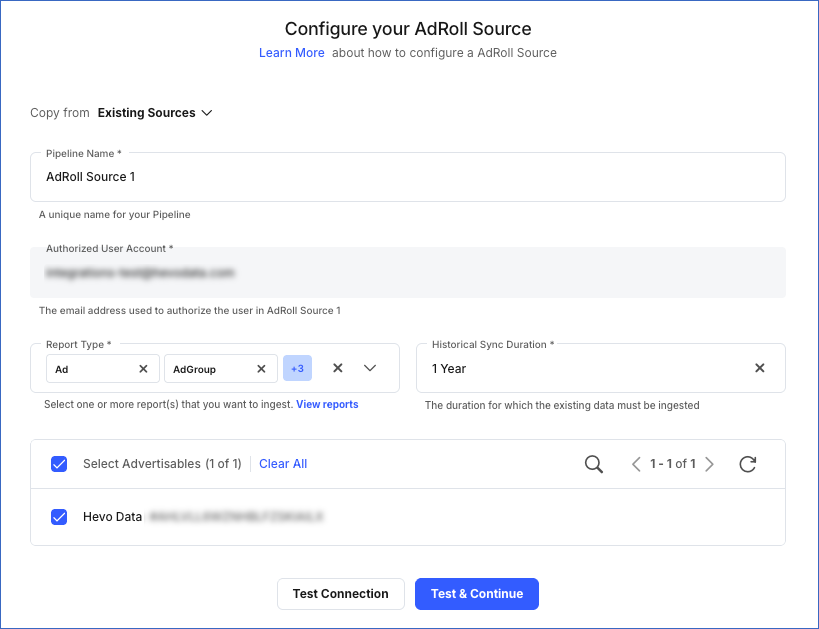
On the Configure your AdRoll Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Authorized User Account (Non-editable): The email address that you selected when connecting to your AdRoll account. This value is pre-filled.
-
Report Type: The list of reports whose data you want Hevo to ingest, for the advertisables you select next.
Note: A distinct object is created for each report of every advertisable you select.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 1 Year.
Note: If you select All Available Data, Hevo ingests all the data available in your Adroll account since January 01, 2017.
-
Advertisables: The list of advertisables from your AdRoll account whose data you want Hevo to ingest.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 48 Hrs | 1-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The historical data is ingested using the Recent Data First approach up till the configured historical sync duration, but no earlier than January 1, 2017, as defined by the AdRoll team.
-
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports as per the ingestion frequency.
-
Data Refresh: Data for all reporting objects is refreshed on a rolling basis to update any conversions attributed to clicks for the past 48 hours, as AdRoll deems data to be finalized post that duration only.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
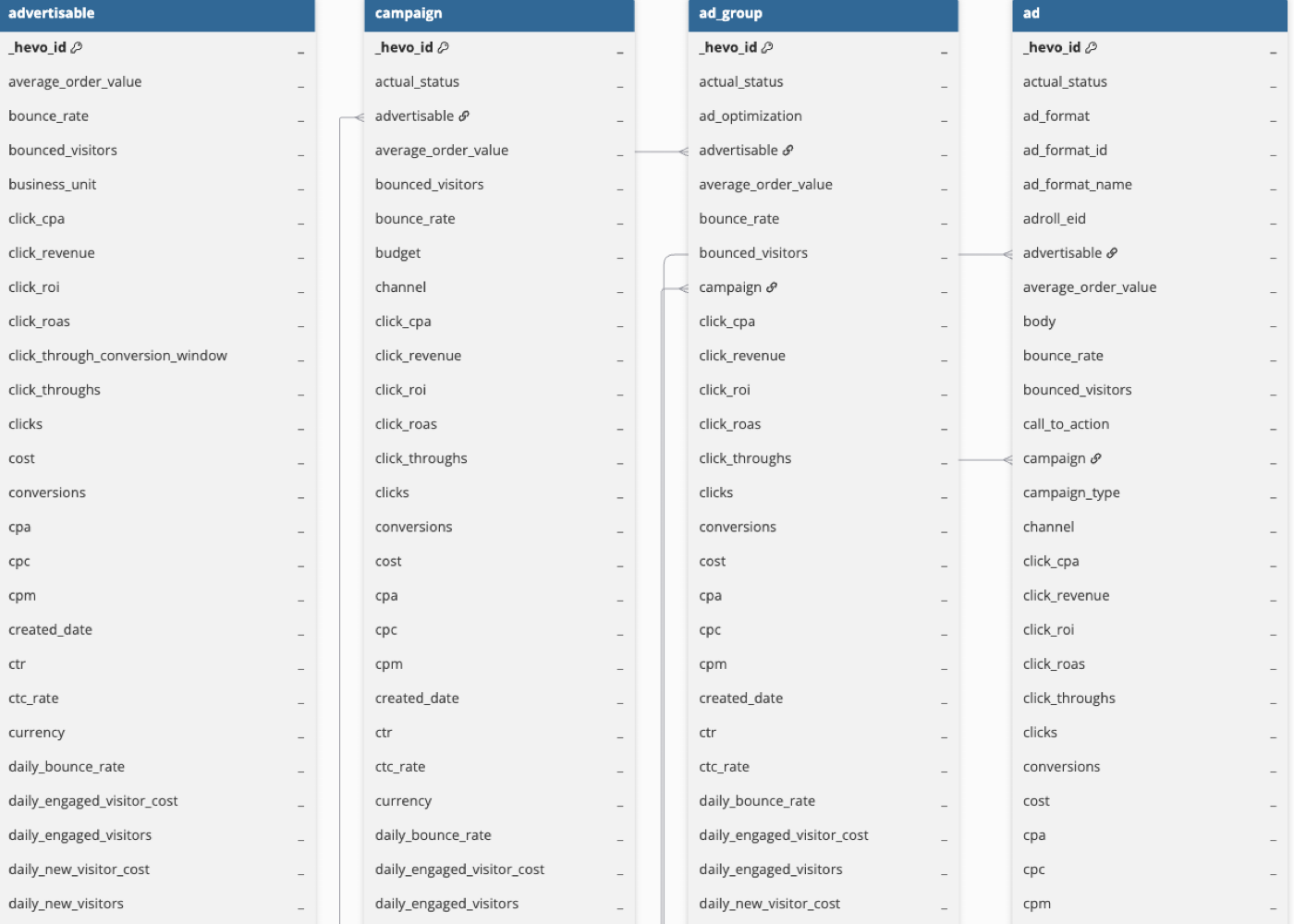
Note: Read Adroll API for the complete list of objects that can be created.
Data Model
Hevo uses the following data model to ingest data from your AdRoll account:
| Object | Description | Primary Keys to create __hevo_id
|
|---|---|---|
| Ad | Advertiser-level, detailed daily report that fetches data for all organisations. |
eid, date, advertisable, campaign, in_adgroup_eid
|
| Adgroup | Ad group-level, detailed daily report that fetches data for all the target audience-specific ads. |
eid, date, advertisable, campaign
|
| Advertisable | Ad-level, daily report that fetches metrics for all creatives that are shown to target audiences. |
eid, date
|
| Audience | Audience-level aggregated data. |
eid, advertisable, campaign
|
| Campaign | Campaign-level, detailed daily report that fetches data for all organisations. |
eid, date, advertisable
|
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring AdRoll as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Adroll as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-05-2023 | NA | Updated section, Configuring AdRoll as a Source as per the latest Hevo UI. |
| Feb-20-2023 | NA | Updated section, Configuring Adroll as a Source to update the information about historical sync duration. |
| Sep-05-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Jul-26-2021 | NA | Added a note in the Overview section about Hevo providing a fully-managed Google BigQuery Destination for Pipelines created with this Source. |