Query Modes
On This Page
Starting Release 2.19, Hevo has stopped supporting XMIN as a query mode for all variants of the PostgreSQL Source. As a result, you will not be able to create new Pipelines using this query mode. This change does not affect existing Pipelines. However, you will not be able to change the query mode to XMIN for any objects currently ingesting data using other query modes.
Hevo queries the Source to ingest data. Querying can differ depending on the type of Source. Read the following sections to know how Hevo performs queries in case of SaaS, and Relational database Sources.
Relational Database Sources
Hevo performs SQL queries on the Source database to get data. You can select different modes to query for the data to be ingested from relational databases such as Amazon Aurora MySQL, Amazon Redshift, SQL Server, MySQL, and PostgreSQL.
Watch a video for an overview of query modes
Hevo allows you to choose the query mode for every object as shown in the image below:
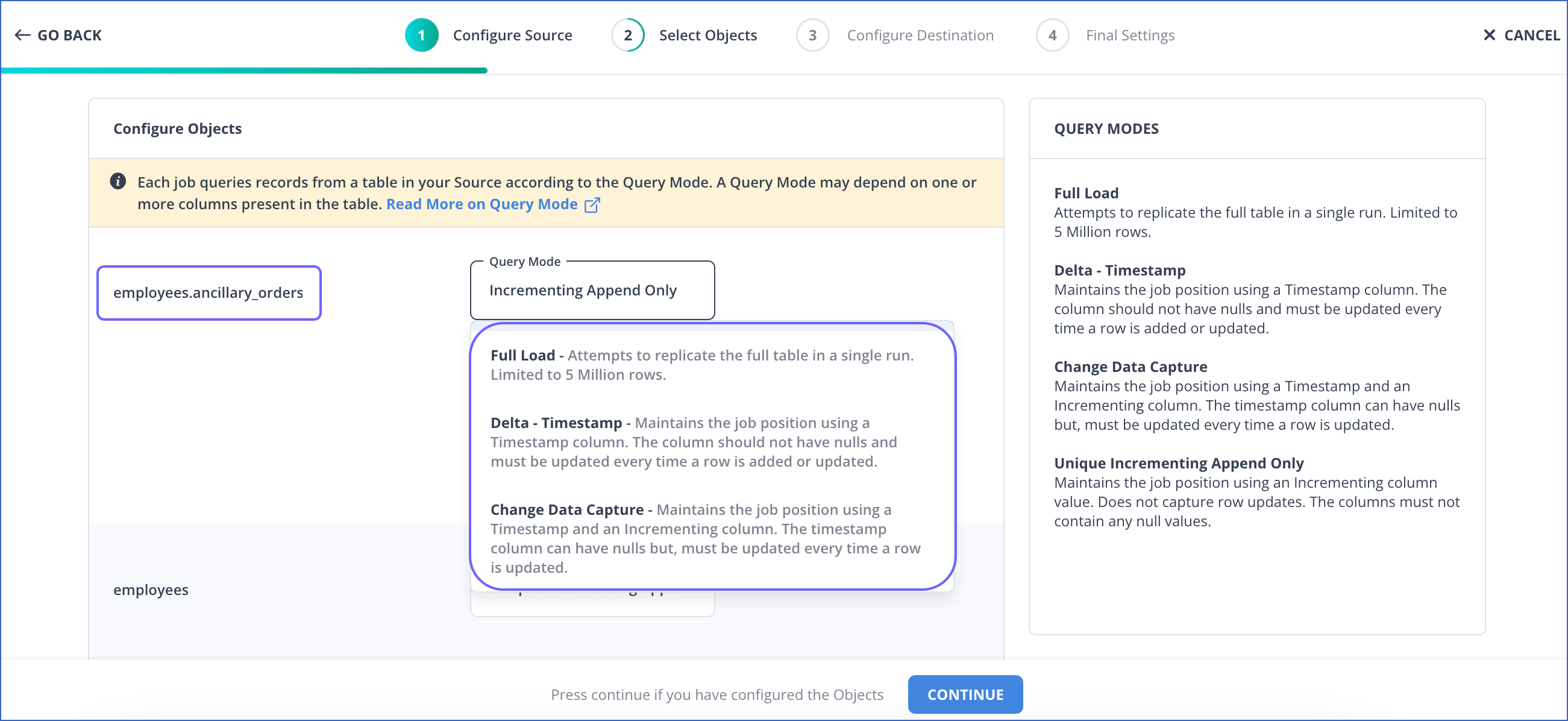
Querying options are particularly useful where you do not want to or do not have the option to set up the database replication logs.
If you change the query mode:
-
The ingestion job restarts from the beginning. For example, if you change the query mode from Unique Incrementing Append Only to Change Data Capture, the entire data is ingested again from the beginning.
-
The re-ingested Events are considered to be historical data and are not billed.
Hevo supports the following query modes:
Full Load
In Full Load, Hevo ingests all the data from the Source table on each ingestion run and loads it to the Destination. Once the entire table is loaded, Hevo waits six hours to ingest data from it again.
This mode is used when the table has up to 5 Million rows. If your Source table contains more than 5 Million rows, you should consider using a different query mode.
Note: Changing the query mode for a Source table causes the ingestion job to restart from the beginning.
The following query is used to fetch the Full Load data:
SELECT * FROM table
LIMIT 5000001 OFFSET 0;
Note: From Release 2.19 onwards, the ingestion limit for Pipelines created with any variant of the PostgreSQL Source has been increased to 25 Million rows. You need to contact Hevo Support to change the default limit from 5 Million to 25 Million rows.
In log-based Pipelines, the query mode is used only to ingest the historical data. If any index or timestamp column is available for a table, that is used to fetch the data. Hence, the Full Load mode is not made available for selection even if you try to edit a table’s query mode post-Pipeline creation.
If change tracking is enabled for a table in the SQL Server Source, the Full Load mode is not shown.
Unique Incrementing Append Only
This mode is useful when the rows in the table are immutable and the data is only being appended to the table.
Unique Column Names: Hevo uses one or more existing auto-incrementing columns in the Source table to keep track of the last ingested ID that it recorded. These columns should individually or together uniquely identify a record. While configuring objects, you can either select the auto-incrementing columns suggested by Hevo or define them yourself. You can choose a combination of the Hevo-suggested and custom columns from the drop-down, or specify them as a comma-separated list. The selected columns jointly act as a unique identifier.

Note: The selected auto-incrementing columns must be of a numeric data type, such as INTEGER, FLOAT, or DOUBLE. Using non-numeric columns such as VARCHAR or BOOLEAN will result in ingestion failure, as Hevo uses that column to detect new records by comparing its values across ingested Events. For this to work reliably, the column’s values must be consistently increasing. Additionally, the column should not contain any NULL values, since Hevo depends on valid numeric entries to identify the last successfully ingested event and detect new ones. If the column contains NULL values, Hevo defers the ingestion for that object until either a valid auto-incrementing column is selected or the values are updated.
Hevo runs the respective queries at the configured frequency for the following scenarios:
-
If only one auto-incrementing column is specified:
SELECT * FROM table WHERE `id_column` > last_polled_id ORDER BY `id_column` ASC LIMIT 1000000;Example:
Consider the following snapshot of a Source object with two records:

Here, User ID is the unique incrementing column. Once these records are ingested, Hevo stores the highest value of User ID as the
last_polled_id, which in this case is 2.
Now, suppose record 1 is changed, and record 3 is added in the Source. When Hevo performs the SQL query, record 1 is ignored, record 3 is picked up and the value of
last_polled_idis modified to 3.
Note: If no new records are added to the Source object since the last fetch, then the UIAO query mode does not return a result.
-
If two or more auto-incrementing columns are specified:
SELECT * FROM table WHERE (`id_column1` > last_polled_id1) OR (`id_column1` = last_polled_id1 AND `id_column2` > last_polled_id2) ORDER BY `id_column1` ASC, `id_column2` ASC LIMIT 500;Example:
Consider the following snapshot of a Source object with four records:

Here, Dept ID and Employee ID are both incrementing columns. While these columns may contain duplicate values, together they uniquely identify a record. The OR condition defined in the query above ensures that the last record fetched has the highest value in both the columns. So, once these four records are ingested, Hevo stores the highest values of Dept ID and Employee ID as
last_polled_id1andlast_polled_id2, which in this case is 2 and E02, respectively.
Now, suppose the record corresponding to Dept ID 1 and Employee ID E01 is changed, and a new record with Dept ID 2 and Employee ID E03 is added in the Source. When Hevo performs the SQL query, it first checks whether there are any records with Dept ID > the
last_polled_id1, which is 2. If it does not find any, it checks within all the records with Dept ID 2 to locate any with Employee ID >last_polled_id2, which is E02. So, while the modified record gets ignored, the new record is picked up because its value for the Employee ID column (E03) is higher than thelast_polled_id2. The value oflast_polled_id2is now modified to E03.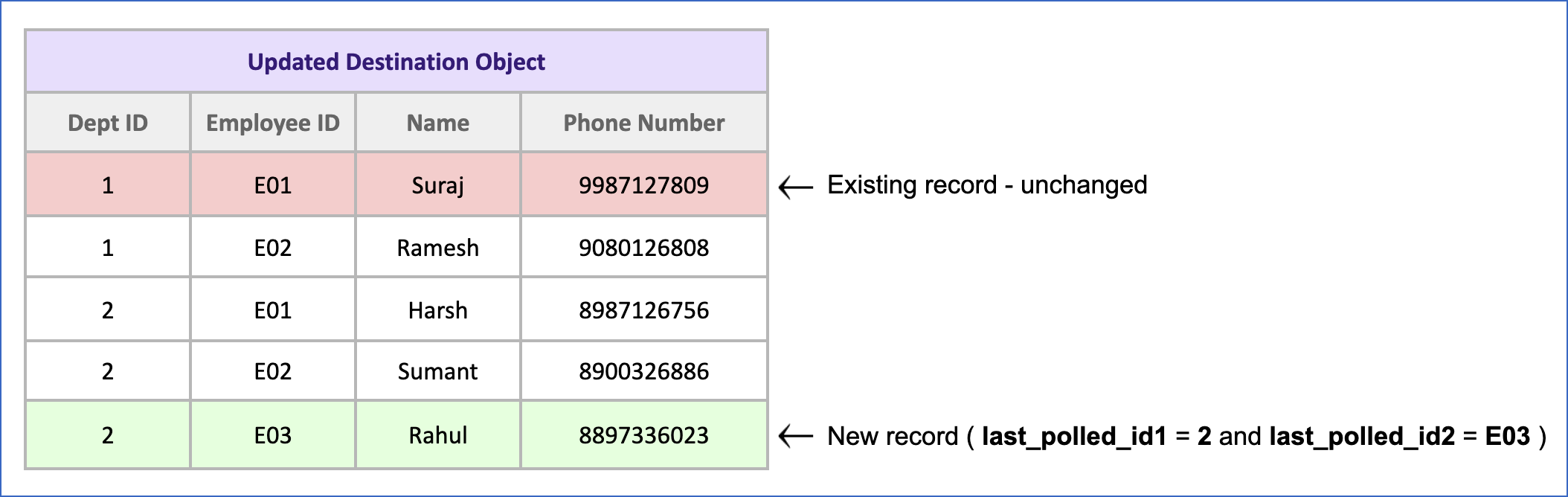
Note: While using the UIAO query mode, ensure that the incrementing columns you specify can identify all new records according to the conditions defined in the SQL query. In the above example, suppose a new record with Dept ID 1 and Employee ID E03 is added in the Source. It will not be ingested because the
last_polled_id1is set to 2. As a result, only records with Dept ID 2 or higher are considered for ingestion.If no new records are added to the Source object since the last fetch, then the UIAO query mode does not return a result.
Delta - Timestamp
This mode is similar to Unique Incrementing Append Only. However, instead of an incrementing ID, Hevo asks you for a Timestamp Column and queries your Source table based on it.
This mode is useful when:
-
The table is appended with new records and a timestamp is maintained.
-
The data in the table is updated and the updated timestamp is maintained.
This mode works efficiently when the table contains up to 1 Million rows with the same timestamp. If this limit is exceeded, Hevo may:
-
Ingest only the first 1 million records and then repeatedly fetch the same set in subsequent runs.
-
Consume a higher number of Events from your quota.
If your Source table contains more than 1 Million rows with the same timestamp, consider using a different query mode, such as Change Data Capture (CDC).
The conditions mentioned above are required to ensure data integrity between your Source and Destination data.
Note: If your tables do not have a timestamp column, you can use Log-based ingestion mode to track updates to existing records.
You must specify the following when configuring this query mode in your Pipeline:
-
Timestamp Column Name: Hevo uses this column to query the Source table and track the value of the
updated_timestamp_column. -
Timestamp Column Delay: Hevo uses this value to accommodate any lag caused by long-running transactions and or out-of-order updates.
Note: The columns you specify for this query mode must exist in the Source table.
Hevo runs the following query to ingest the data from your Source at the configured frequency:
SELECT * FROM table
WHERE `updated_timestamp_column` > last_polled_time AND
`updated_timestamp_column` < now() - delay
ORDER BY `time_column` ASC
LIMIT 1000000;
In the query above, Hevo identifies the data to be ingested using the last_polled_time as the lower limit and the current time, given by the now() function, as the upper limit.
Hevo sets the value of last_polled_time as follows:
-
In the first run of the Pipeline, Hevo sets the
last_polled_timeto the Unix Epoch, 1970-01-01 00:00:00.0 UTC. -
Once data is ingested, Hevo updates the
last_polled_timeto the latest timestamp from the records ingested in the previous batch.
Example:
Consider the following snapshot of a Source object with two records:

Here, Update TS is the updated_timestamp_column. Once these records are ingested, Hevo stores the latest timestamp of Update TS as the updated_timestamp_column value, which is Fri, 16 Apr 2021 06:10:51 GMT.

Now, suppose record 1 is changed and record 3 is added. When Hevo runs the SQL query, record 1 is picked up, record 3 is ignored, and the value of updated_timestamp_column is modified to Fri, 16 Apr 2021 07:10:51 GMT.

Change Data Capture
This mode is a mixture of both Unique Incrementing Append Only and Delta - Timestamp modes. The mode is useful for capturing both inserts and updates.
You must specify the following when configuring this query mode in your Pipeline:
-
Auto-Incrementing Column: Hevo uses this column to keep a track of the last ingested ID it recorded.
Note: The selected column must be of a numeric data type, such as INTEGER, FLOAT, or DOUBLE. Using non-numeric columns, such as VARCHAR or BOOLEAN, will cause ingestion failure. This is because Hevo detects new records by comparing values in the auto-incrementing column across ingested Events. For reliable ingestion, the column’s values must increase consistently.
-
Update Timestamp Column: Hevo uses this column to query the Source table and to keep track of
updated_timestamp_columnvalue. -
Timestamp Column Delay: This configuration can be used when you want to replicate data with a delay which is useful when there are long-running transactions or it is a design requirement. Enter the delay (in milliseconds) you want to introduce to the query.
Note: The columns you specify for this query mode must exist in the Source table.
Hevo runs the following query at the configured frequency.
SELECT * FROM table
WHERE (`updated_timestamp_column` < now() - delay AND
((`updated_timestamp_column` = last_polled_time AND
`id_column` > last_polled_id) OR
`updated_timestamp_column` > last_polled_time)) OR
(`updated_timestamp_column` is NULL AND
`id_column` > last_polled_null_id)
ORDER BY `updated_timestamp_column`, `id_column` ASC
LIMIT 500;
Example:
Consider the following snapshot of a Source object with two records:

Here, User Id and Update TS are the last_polled_id and updated_timestamp_column respectively. Once these records are ingested, Hevo stores the latest values of User Id and Update TS as the last_polled_id and updated_timestamp_column value, which in this case are 2 and Fri, 16 Apr 2021 06:10:51 GMT respectively.

Now, suppose record 1 is changed, and record 3 is added in the Source. When Hevo performs the SQL query, records 1 and 3 are picked up and the values of last_polled_id and updated_timestamp_column are modified to 3 and Fri, 16 Apr 2021 07:10:51 GMT respectively.

Change Tracking
This mode makes use of the Change Tracking (CT) feature provided by SQL Server. To use this mode, Change Tracking must be enabled at both the database level and for each Source object (table) you want to track. To avoid data loss, the change retention period should be more than the replication frequency of your Hevo Pipeline.
Note: Hevo recommends that you set the retention period to 3 days. This reduces the risk of log expiry in Pipelines with a low ingestion frequency, such as 24 hours.
Hevo uses CT instead of Change Data Capture (CDC) for some Sources as CT requires less data to be managed and stored at the Source. CT replicates the historical data changes and Hevo pushes these changes to the Destination in near real-time, compared to CDC which maintains all the historical changes to the data at the Source.
CT captures only the primary key of changed records and the type of operation (insert, update, or delete). Hevo uses this information to identify changes by querying SQL Server’s internal change tracking tables using built-in system functions. These queries return the list of inserted, updated, or deleted records since the last replication.
Note: CT does not track column-level changes or store the old values of records.
In contrast, CDC logs complete row-level changes, including old and new values, column-level modifications, and transaction context.
Note: When configuring this query mode in the Hevo Pipeline, you must specify columns that already exist in the Source table.
Example:
If a row with ID=1 and Name='Alice' is updated to Name='Alicia':
-
CT will track:
ID=1 was updated -
CDC will track:
ID=1 changed from 'Alice' to 'Alicia'
SaaS Sources
To extract data from a SaaS Source, Hevo uses the respective Source’s API. Therefore, selection of query mode does not apply to a SaaS Source. The specifications of the Source API affect how data is queried for different objects in the Source.
For example, in case of certain objects, the Source API may allow ingestion of incremental data, that is, any new and updated Event. For other objects, it may allow Hevo to perform only a Full Load of the object, which means that the entire data in the object is replicated on each ingestion. The objects Videos, Channels, and Playlists in YouTube Analytics, and Audience in AdRoll are examples of Full Load objects.
For a few SaaS Sources, to reduce the Events quota consumption of Full Load objects, Hevo filters the data and loads only the new and updated data of the object to the Destination.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Aug-21-2025 | NA | Updated the Delta - Timestamp section to add information on the behavior when a Source table contains more than 1 Million rows with the same timestamp. |
| Aug-14-2025 | NA | - Added information that columns specified while configuring query modes must exist in the Source table. - Updated section, Change Data Capture to add a note about supported data types for the auto-incrementing column. |
| Aug-01-2025 | NA | Updated section, Change Tracking to highlight difference between CT and CDC. |
| Jun-30-2025 | NA | Updated section, Unique Incrementing Append Only to add note about supported data types for the incrementing column. |
| Apr-10-2025 | NA | Added clarification about data integrity when using the Delta - Timestamp query mode. |
| Jul-01-2024 | NA | Updated sections, Full Load and Unique Incrementing Append Only to reflect the supported functionality. |
| Jun-17-2024 | 2.24.1 | Added clarification about providing columns as a comma-separated list in the UIAO mode. |
| Jan-22-2024 | 2.19.2 | Updated section, Unique Incrementing Append Only to add information about selection of multiple auto-incrementing columns. |
| Jan-10-2024 | 2.19 | - Removed section, XMIN. - Removed mentions of XMIN as a query mode. |
| Jul-14-2023 | NA | Updated section, Unique Incrementing Append Only to add note regarding non-nullable auto-incrementing column. |
| Jun-28-2023 | 2.14 | Updated section, XMIN to add information about the default query mode selected for Pipelines created for PostgreSQL Sources. |
| Feb-10-2023 | NA | Updated section, Full Load to specify how this mode is used for different Sources and ingestion modes. |
| Feb-07-2023 | 2.07 | Updated section, XMIN for better clarity. |
| Jan-10-2023 | NA | Updated section, Delta-Timestamp to add information about using Log-based ingestion to track updates to records in your table in case it does not have a timestamp column. |
| Nov-08-2022 | NA | Moved under Ingestion Modes and Query Modes. |
| Apr-25-2022 | NA | Updated section, Relational Database Sources. |
| Apr-11-2022 | NA | Added section, SaaS Sources to include information about Full Load objects for Saas Sources. |
| Dec-20-2021 | NA | Updated section, Full Load to add a note about XMIN, an alternative to Full Load query mode. - Updated section, XMIN to add a link to the FAQ about changing the query mode. |
| Nov-09-2021 | 1.75 | Added the section, XMIN, to explain the new XMIN query mode available for PostgreSQL Sources. |
| Sep-09-2021 | 1.71 | - Renamed Delta - Append Only to Unique Incrementing Append Only as per UI. - Updated the section, Change Tracking. - Added examples for all query modes. |
| Aug-09-2021 | NA | Updated the section, Change Tracking. |
| Jun-28-2021 | 1.61 | Updated the Full Load section with information about ingesting more than 5 Million rows. |
| Jun-01-2021 | NA | Updated the page overview to explain the Hevo app behavior in case changes are made to the query mode. |