UserVoice
On This Page
UserVoice is a product feedback collection and management platform that enables you to gather feedback on your product from your target audience and make data-driven decisions based on that feedback. It is used by product managers and customer facing teams for prioritising product improvements based on the customer feedback analysis.
You can replicate the data from your UserVoice account to a Destination database or data warehouse using Hevo Pipelines. Hevo ingests the data objects in Full Load mode. Refer to section, Data Model for the list of supported objects.
UserVoice uses an API token to identify Hevo and authorize the request for accessing account data.
Prerequisites
-
An active UserVoice account from which data is to be ingested exists.
-
The API token is available to provide Hevo access to your UserVoice account data.
-
You are logged in as an Admin user to create the API token. Else, you can obtain the token from your administrator. Read Managing Permissions to know about the different types of users, and the permissions they have in UserVoice.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the API Token
You require an API token to authenticate Hevo on your UserVoice account. The API token does not expire and can be reused for all your Pipelines.
Note: You must log in as an Admin user to perform these steps.
To create the API token:
-
Log in to your UserVoice account as an Admin user.
-
In the left navigation pane, click on the Settings (
 ) icon, and then click Integrations.
) icon, and then click Integrations.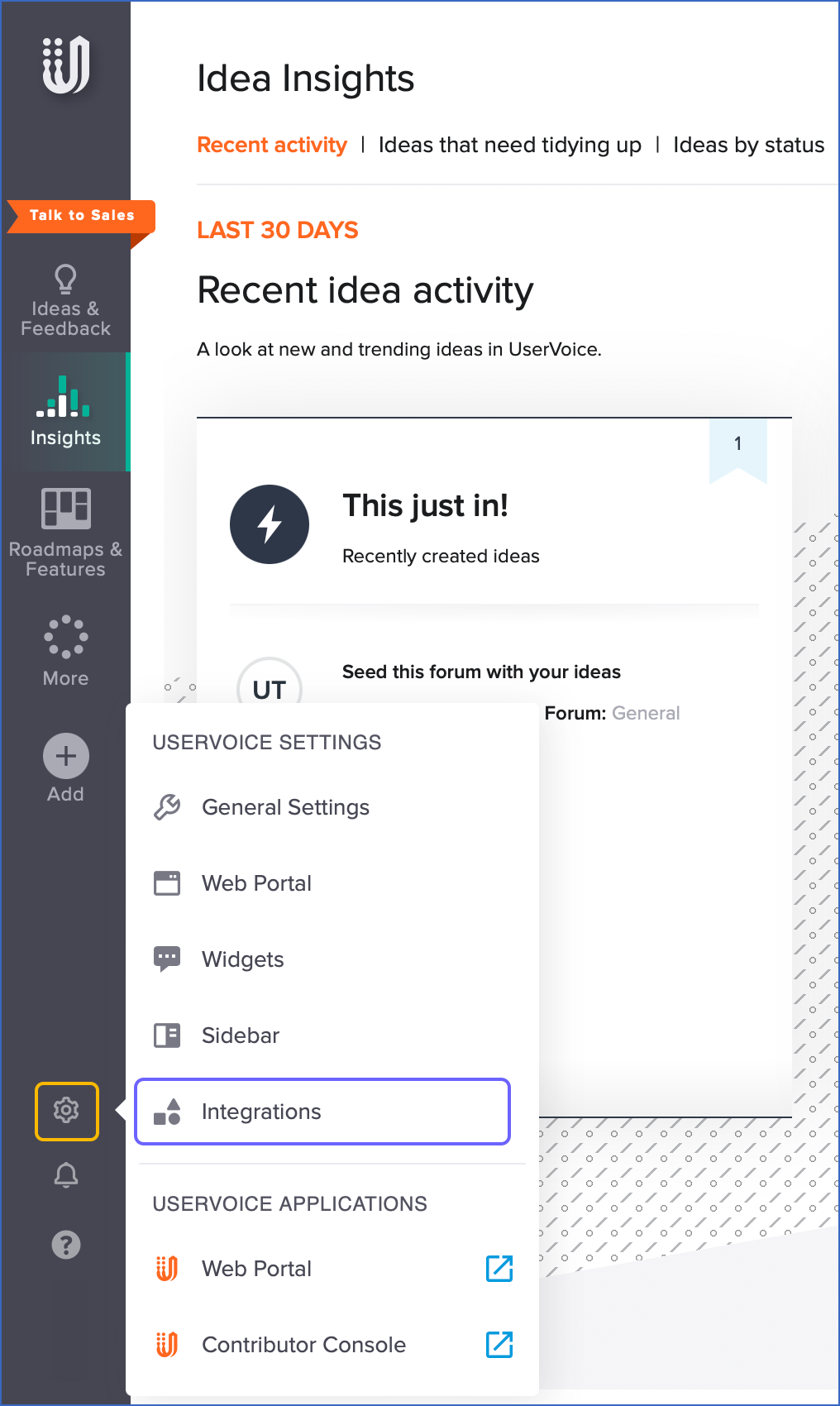
-
On the Settings page, Integrations tab, under the Essential Plan Integrations section, click UserVoice API keys.
-
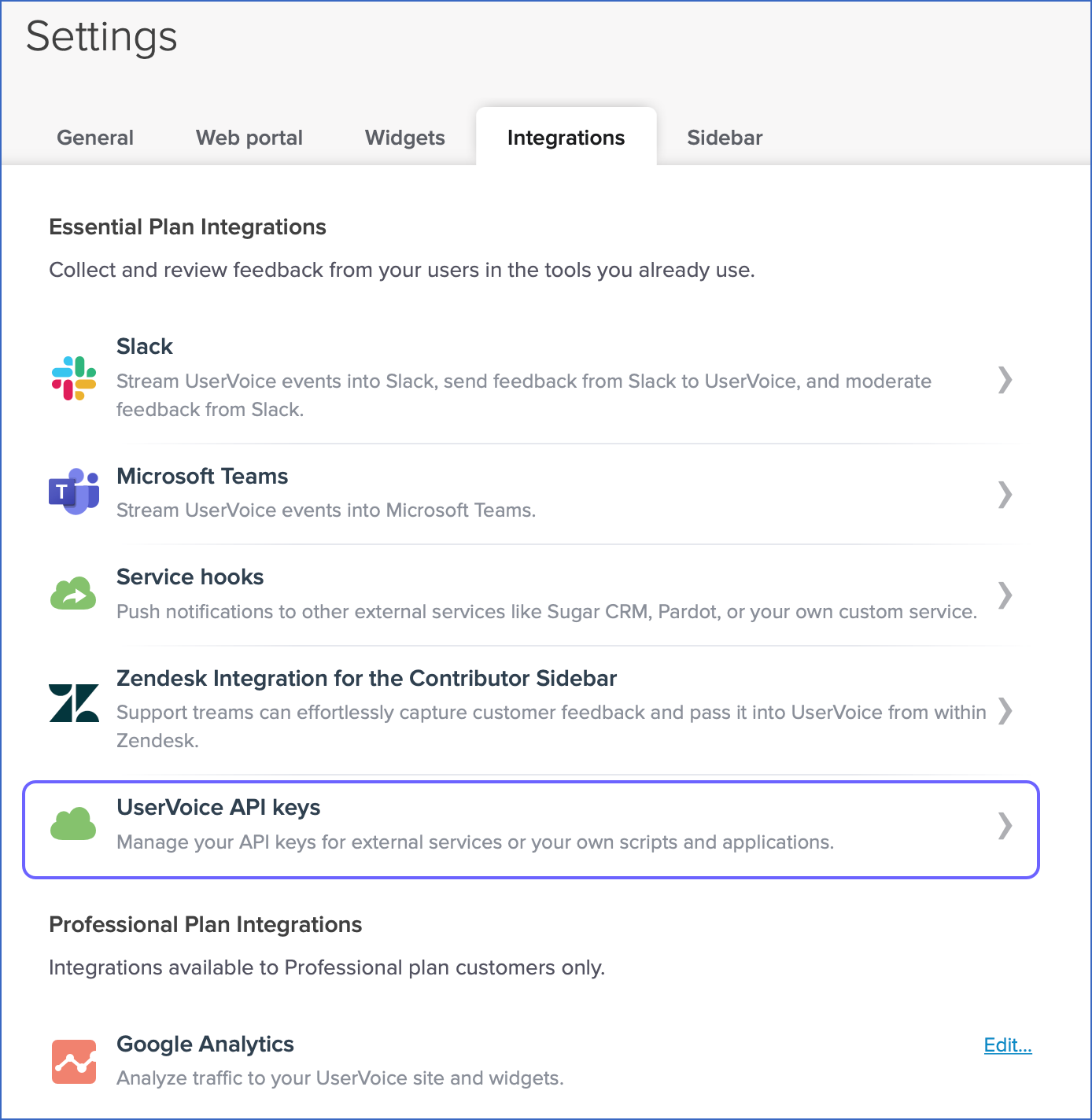
Click Add API key.

-
In the Add API key pop-up window that appears, do the following:
-
Specify a NAME for the API key.
-
Select the TRUSTED? check box.
-
Click Add API key.
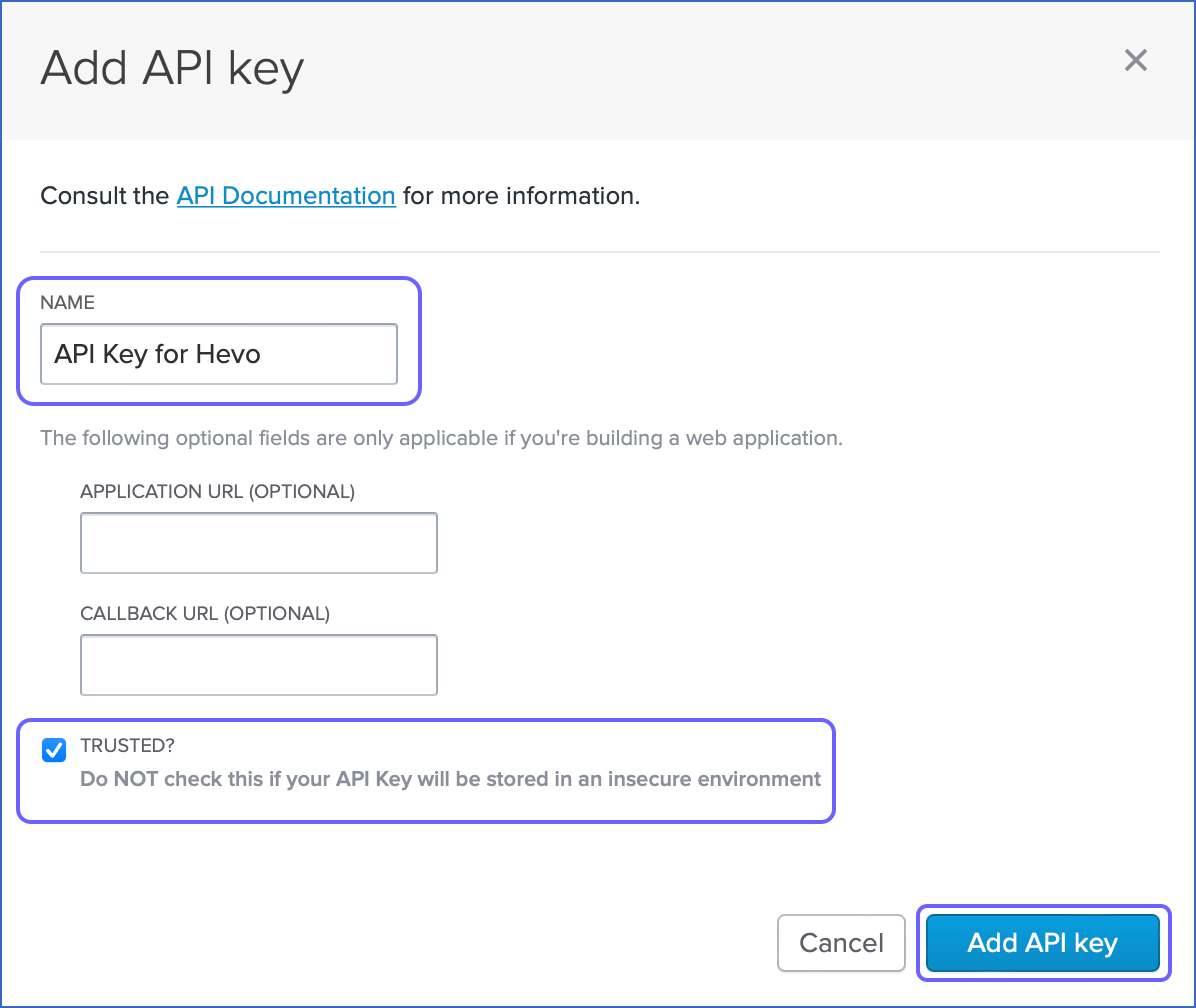
Your API key is now visible under the UserVoice API keys section.
-
-
Click Create corresponding to the API key that you created.
-
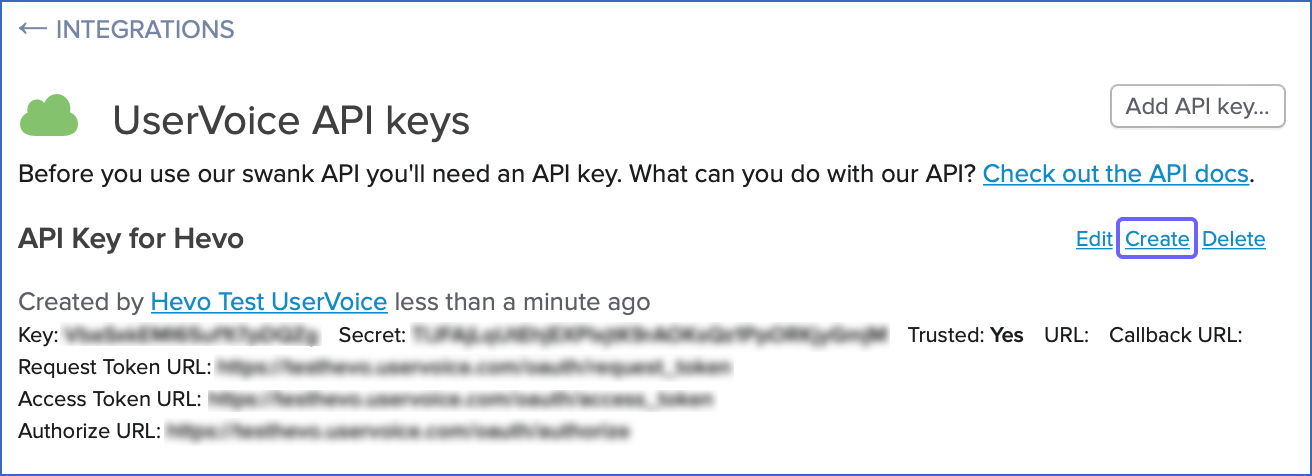
Copy the API token and save it securely like any other password. Use this token while configuring your Hevo Pipeline.
Configuring UserVoice as a Source
Perform the following steps to configure UserVoice as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select UserVoice.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
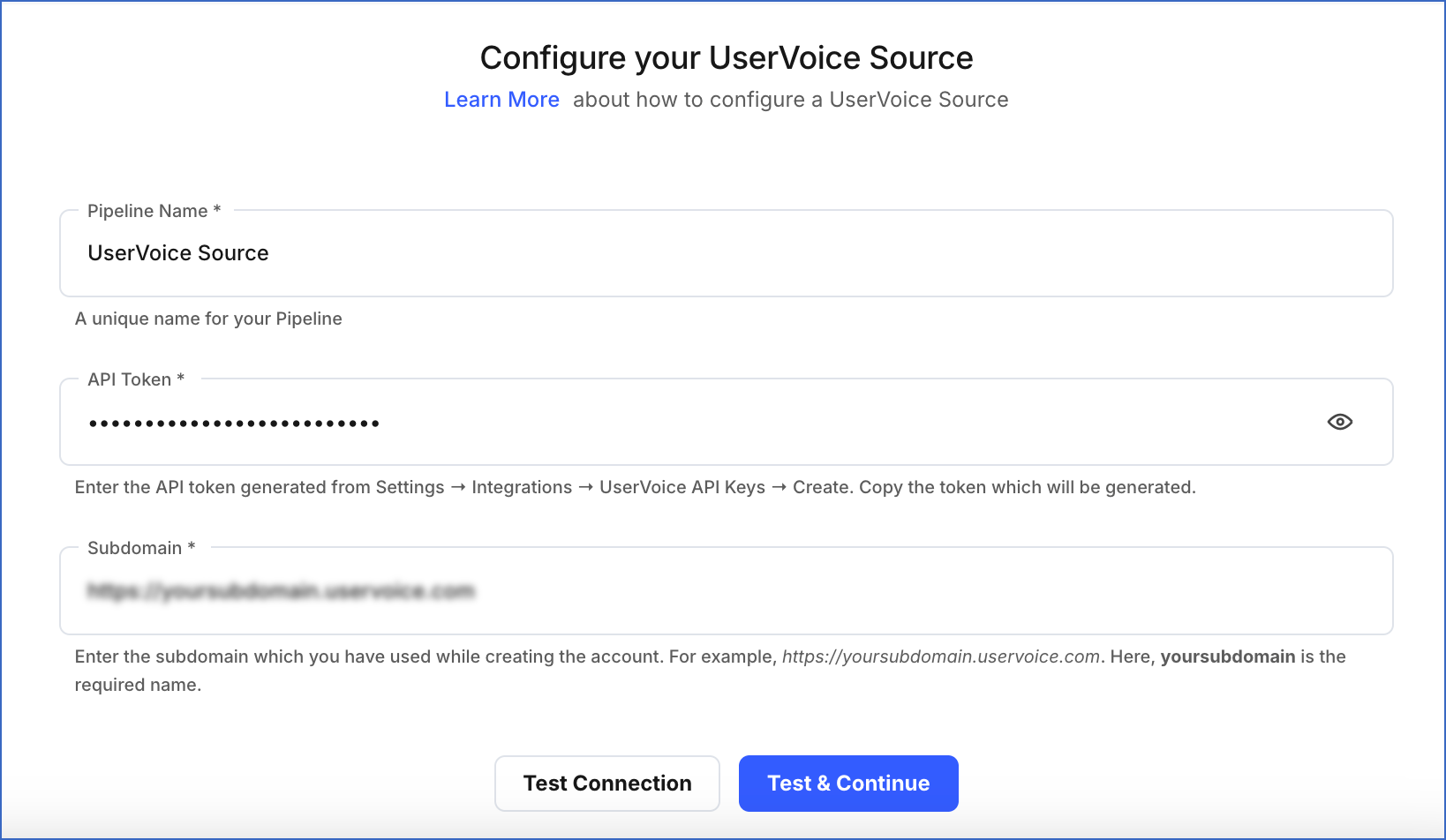
On the Configure your UserVoice Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
API Token: The API token that you created in your UserVoice account.
-
Subdomain: The subdomain of your UserVoice site URL. For example, if your site URL is https://hevotest.uservoice.com, then the subdomain is hevotest.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Hevo ingests all the objects in Full Load mode in each run of the Pipeline.
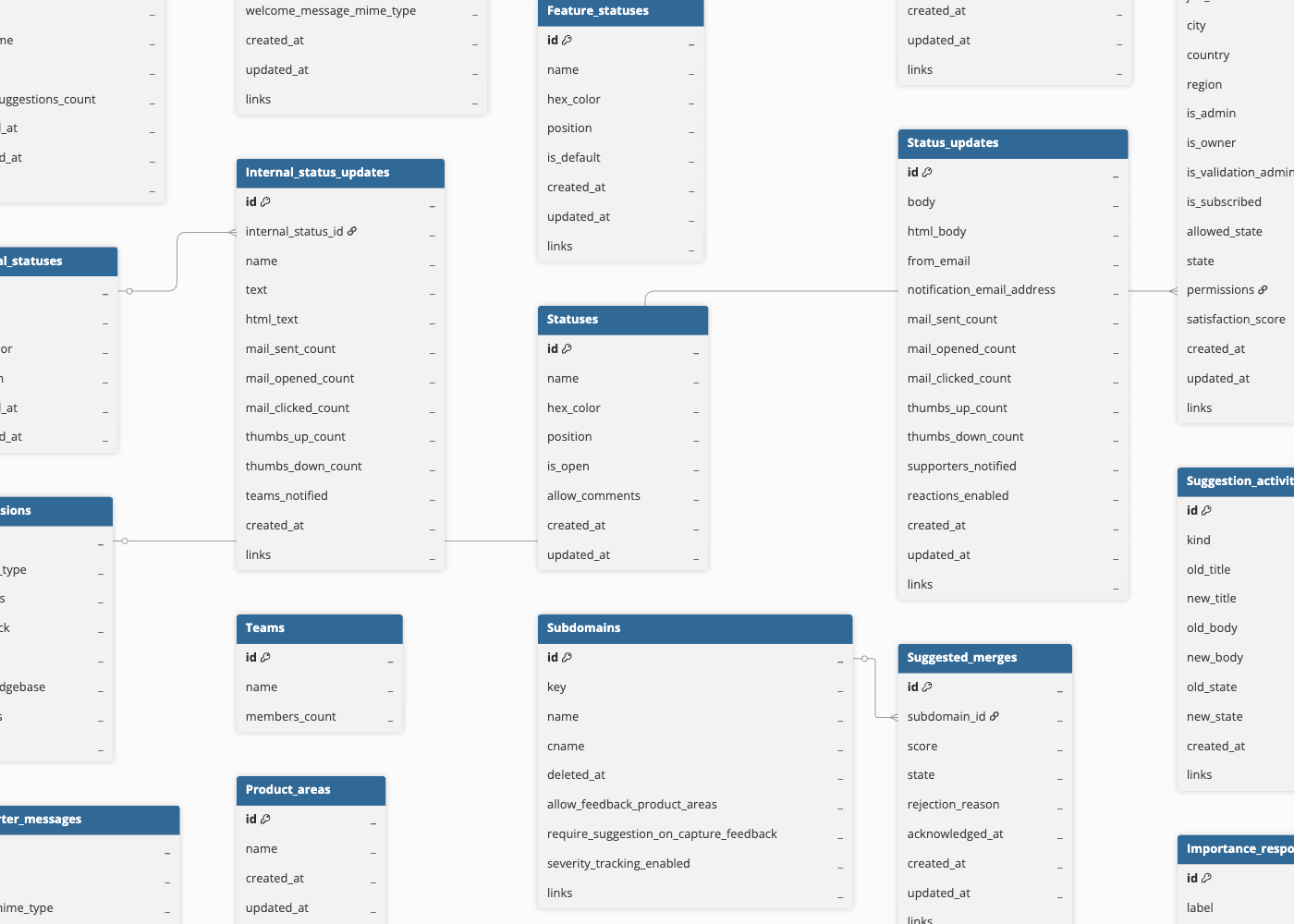
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Objects | Mode | Description |
|---|---|---|
| Attachments | Full Load | Contains the details of the files that you uploaded to your UserVoice account. |
| Categories | Full Load | Contains the details of the categories used to classify suggestions in a forum. For example, a category named Analytics may contain suggestions related to gathering of information, reporting, and creating of tables and graphs. |
| Comments | Full Load | Contains the details of the various comments made on the suggestions by the forum users. |
| External Accounts | Full Load | Contains the details of the external account, such as a data warehouse, database, and CRM linked to your UserVoice account. |
| External Users | Full Load | Contains the details of the user, such as ID, name, and email imported from external accounts. |
| Feature Statuses | Full Load | Contains the current status of a product feature. |
| Features | Full Load | Contains the details of the feedback received from multiple users, for various features in your product. |
| Feedback Records | Full Load | Contains the details of the feedback received from a user, for various features in your product. |
| Forum Invitations | Full Load | Contains the details such as the email address and form of authentication of the new user for granting them access to the forum. |
| Forums | Full Load | Contains the details of the discussion on suggestions, among end users. |
| Internal Flags | Full Load | Contains the details of the ideas that are considered significant and need attention from the admins of your UserVoice account. |
| Internal Status Updates | Full Load | Contains the details of the updates made to the suggestion’s internal status by the admins of your UserVoice account. |
| Internal Statuses | Full Load | Contains the details of a suggestion’s current status being displayed to the internal teams. |
| Labels | Full Load | Contains the details of the tags used by admins to organize suggestions within your UserVoice account. |
| Notes | Full Load | Contains the details of the internal suggestions communicated by the admins of your UserVoice account. |
| NPS Ratings | Full Load | Contains the details of the responses from users to a question about recommending the product or service to their friends or colleagues. These details are used to measure customer satisfaction. |
| Permissions | Full Load | Contains the details of the various permissions that can be granted to users by the admins of your UserVoice account. |
| Product Areas | Full Load | Contains the details of the groups to which the features are assigned. |
| Segmented Values | Full Load | Contains the details of the supporter metrics for a segment. |
| Segments | Full Load | Contains the details of all the segments in your UserVoice account. A segment is created by filtering users and accounts according to your requirements. |
| Status Updates | Full Load | Contains the details of the updates made to the suggestion’s status by the admins of your UserVoice account. |
| Statuses | Full Load | Contains the details of a suggestion’s current status being displayed to the end users. |
| Suggested Merges | Full Load | Contains the details of the ideas that can be merged together. |
| Suggestion Activity Entries | Full Load | Contains the details of the events that are affecting the suggestions. |
| Suggestions | Full Load | Contains the details of the changes suggested to your product. These changes can be suggested internally by the employees within your company or by your customers. |
| Supporter Messages | Full Load | Contains the details of the messages sent from the admins of your UserVoice account to the supporters of a suggestion. |
| Supporters | Full Load | Contains the details of the users that voted on a suggestion. |
| Teams | Full Load | Contains the details of all the teams belonging to your UserVoice account. These teams are used to classify the feedback captured from users. |
| Users | Full Load | Contains the details of all the users that gather feedback, such as administrators and employees of the company, as well as the end users who provide feedback to the company. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Pagination: Each API response for each UserVoice object fetches one page with up to 100 records.
-
Rate Limit: UserVoice imposes a limit on the number of API calls that can be made in a specific time interval. These rate limits are based on your UserVoice plan. Read Rate Limiting to know more about rate limits in UserVoice.
Limitations
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
The data is loaded in Full Load mode in each Pipeline run. As a result, you cannot load the historical data alone at any time.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Uservoice as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Jul-27-2022 | 1.92 | New document. |