Twitter Ads
On This Page
Twitter Ads is an online advertising platform that allows businesses to reach their desired target audience on Twitter. It can be used to promote content, products, services, events, website traffic, and app downloads. Twitter displays these ads in the form of promoted tweets, accounts, and trend takeovers.
Hevo uses the Twitter Ads API to ingest the data from your Twitter Ads account and replicate it into the desired Destination database or data warehouse for scalable analysis. You must obtain the API keys and tokens to allow Hevo to access data from your Twitter Ads account.
Prerequisites
-
An active Twitter Ads account from which data is to be ingested exists.
-
An active Twitter Developer account exists. If not, read Step one: Signup for a developer account.
-
An active Twitter application from which keys and tokens are to be obtained exists. If not, refer to section, Create a Twitter Application for steps to create one.
-
The keys and tokens are available to authenticate Hevo on your Twitter Ads account. You must be logged in as an Account Administrator, Ad Manager, or Creative Manager to obtain these credentials. Else, you can obtain them from your account administrator.
-
You have access to the Twitter Ads API. Read Step three: Apply for access to the Ads API to know how to access the Twitter Ads API.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Create a Twitter Application (Optional)
You require a Twitter application to generate the keys and tokens needed for configuring Twitter Ads as a Source in Hevo. If you already have an application that you can use, skip to Step 2.
To create a Twitter application:
-
Log in to your Twitter Developer account.
-
In the Dashboard page, under Projects, click +Add App.

-
In the Name your App page, specify the app name and click Next.

-
In the Keys & Tokens page that appears, click Copy corresponding to the API Key and API Key Secret to copy them, and save them securely like any other password. Alternatively, obtain them later from the App settings. You can use these credentials while configuring your Hevo Pipeline.

Obtaining the Keys and Tokens
You require keys and tokens to authenticate Hevo on your Twitter Ads account. These credentials (keys and tokens) do not expire and can be reused for all your Pipelines.
Note: You must be logged in as an Account Administrator, Ad Manager, or Creative Manager to perform these steps.
To obtain the credentials:
-
Log in to your Twitter Developer account.
-
In the Dashboard page, under Projects, PROJECT APP, click the Settings (
 ) icon corresponding to the app for which you want to generate the credentials.
) icon corresponding to the app for which you want to generate the credentials.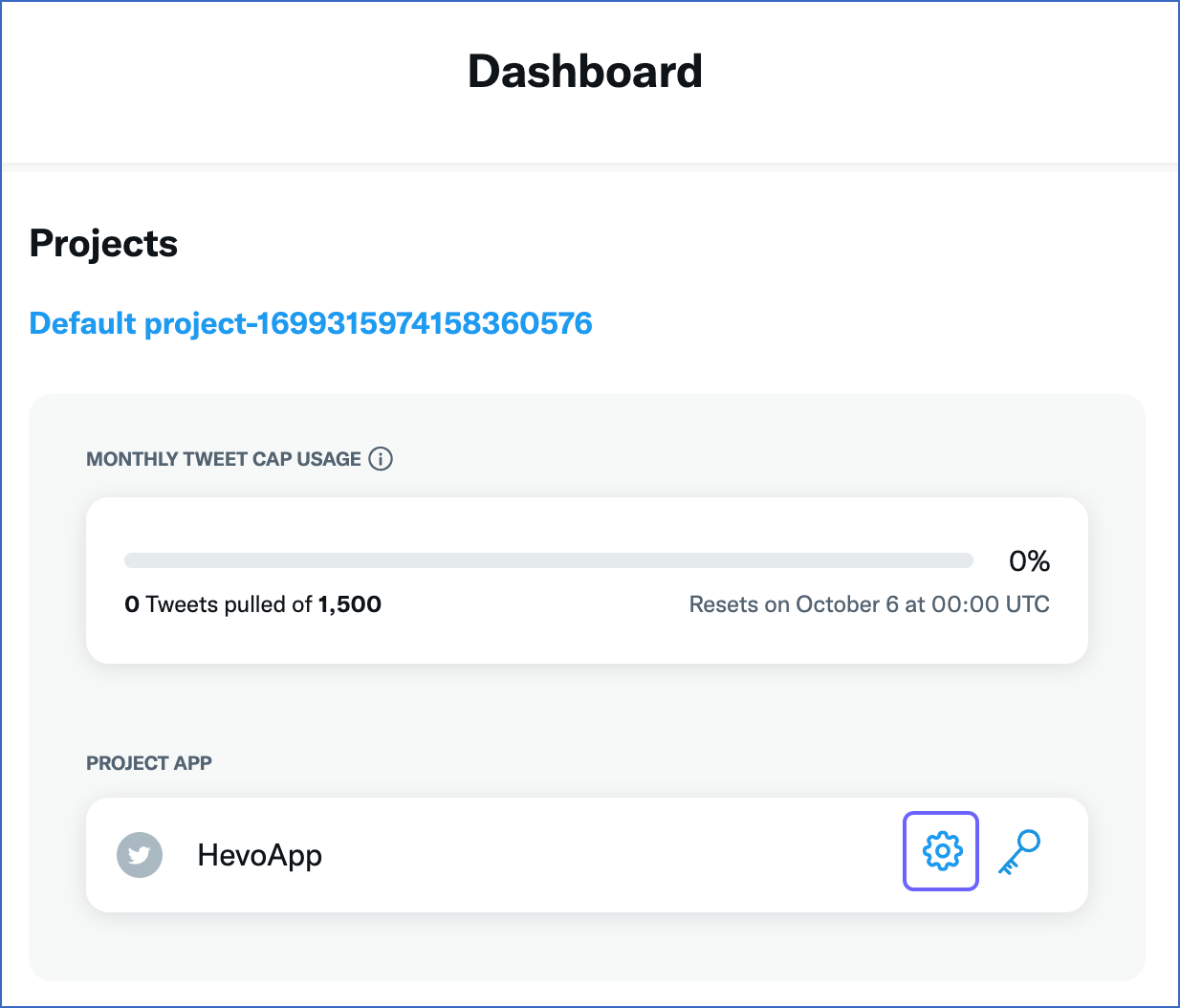
-
In the <Your_App_Name> page, click Keys and tokens.

-
In the page that appears, do the following:
-
In the Consumer Keys section, click Regenerate corresponding to API Key and Secret.

-
In the confirmation dialog, click Yes, regenerate.

-
In the page that appears, click Copy corresponding to the API Key and API Key Secret to copy them, and save them securely like any other password.
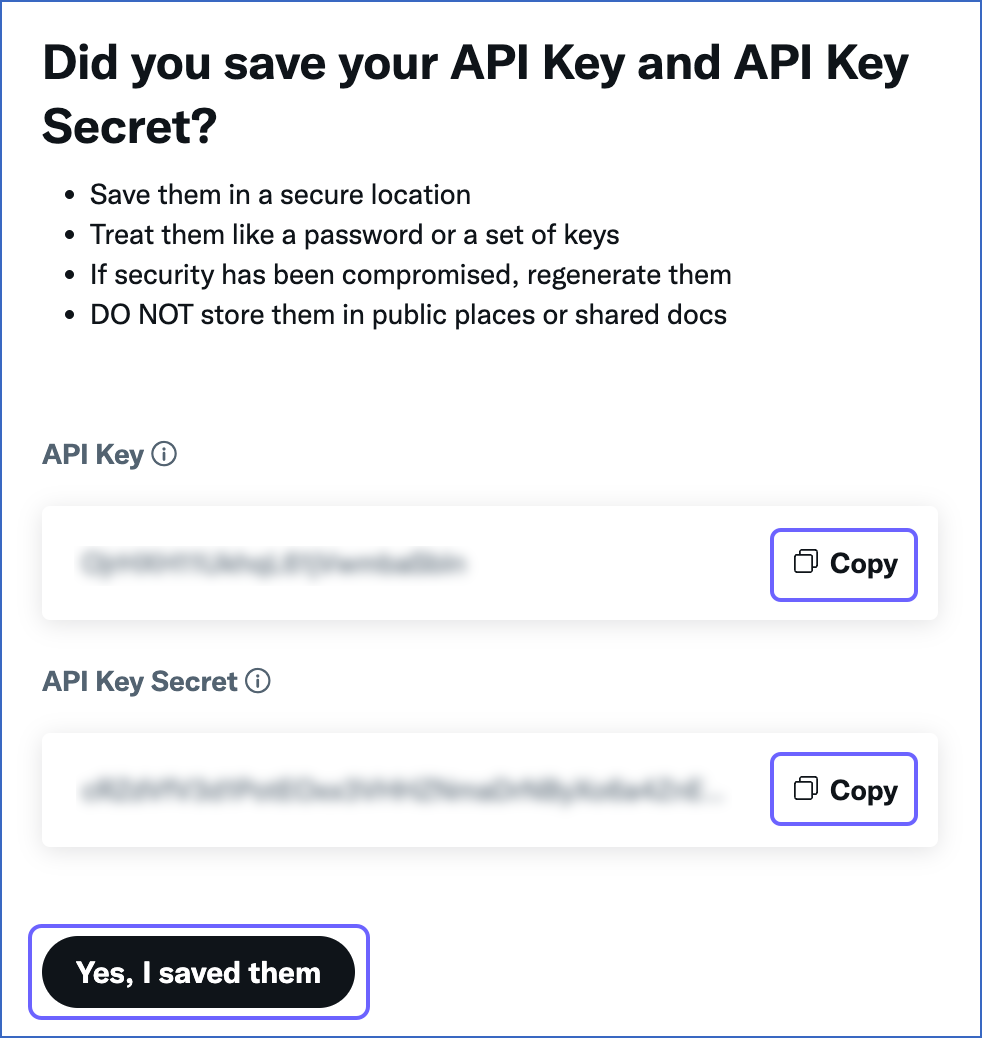
-
Click Yes, I saved them.
-
-
Repeat Step 4 above to obtain the Access Token and Secret from the Authentication Tokens section.
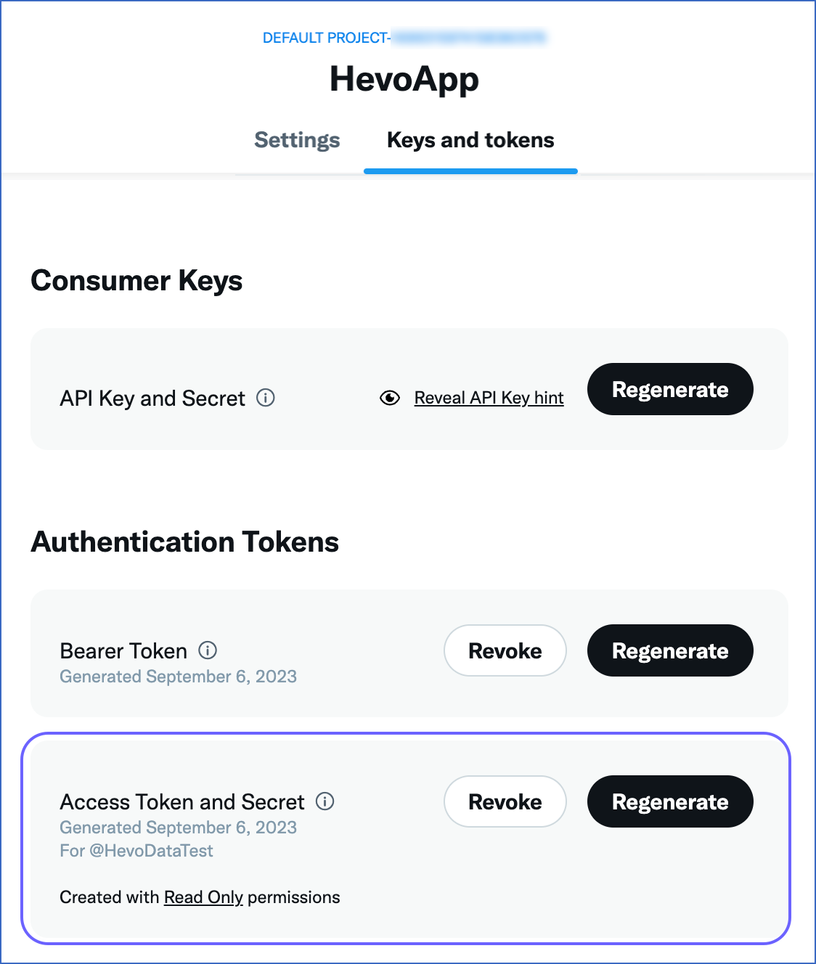
You can use these credentials while configuring your Hevo Pipeline.
Configuring Twitter Ads as a Source
Perform the following steps to configure Twitter Ads as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
In the Select Source Type page, select Twitter Ads.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
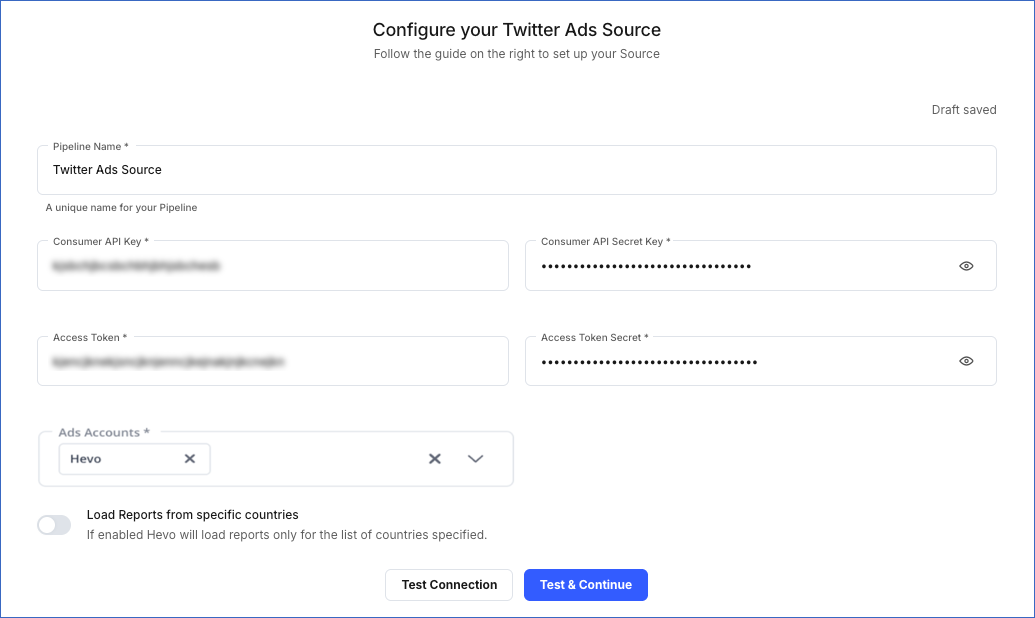
In the Configure your Twitter Ads Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Consumer API Key: The API key that you obtained from your Twitter Ads account.
-
Consumer API Secret: The API secret that you obtained from your Twitter Ads account.
-
Access Token: The access token that you obtained from your Twitter Ads account.
-
Access Token Secret: The access token secret that you obtained from your Twitter Ads account.
-
Ads Accounts: The Twitter Ads account(s) from which you want to replicate the data.
-
Load Reports from specific countries: If enabled, Hevo ingests data only from the countries you select.
If disabled, Hevo ingests all the data available in your Twitter Ads account.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 12 Hrs | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 12 Hrs | 30 Mins | 24 Hrs | 1-24 |
Objects
-
Historical data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Twitter Ads account using the Recent Data First approach.
-
Incremental data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable. Default duration: 12 Hours.
Reports
-
Historical data: In the first run of the Pipeline, Hevo ingests the data of the past 90 days for all the reports in your Twitter Ads account using the Recent Data First approach.
-
Incremental data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports as per the ingestion frequency. Default duration: 12 Hours.
Note: From Release 1.79 onwards, Hevo ingests your historical data using the Recent Data First approach, whereby, the data is ingested in the reverse order, starting from the latest to the earliest. This enables you to have quicker access to the most recent data. This change applies to all new and existing Pipelines.
Schema and Primary Keys
Hevo uses the following primary keys to upload the records in the Destination database:
Primary keys for objects
| Object | Primary Keys |
|---|---|
| ACCOUNTS | ACCOUNT_ID, ID |
| FUNDING_INSTRUMENTS | ACCOUNT_ID, ID |
| CAMPAIGNS | ACCOUNT_ID, ID |
| LINE_ITEMS | ACCOUNT_ID, ID |
| PROMOTED_TWEETS | ACCOUNT_ID, ID |
| MEDIA_CREATIVE | ACCOUNT_ID, ID |
Primary keys for reports
Unsegmented reports
| Report | Primary Keys |
|---|---|
| ACCOUNT_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
| CAMPAIGN_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
| FUNDING_INSTRUMENT_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
| LINE_ITEM_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
| PROMOTED_TWEET_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
| MEDIA_CREATIVE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, PLACEMENT |
Segmented reports
| Report | Primary Key |
|---|---|
| ACCOUNT_AGE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_APP_STORE_CATEGORY_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_DEVICES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| ACCOUNT_EVENTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_GENDER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_INTERESTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_LOCATIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_PLATFORMS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| ACCOUNT_PLATFORM_VERSIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| ACCOUNT_POSTAL_CODES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| ACCOUNT_REGIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| CAMPAIGN_AGE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_APP_STORE_CATEGORY_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_CONVERSION_TAGS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_DEVICES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| CAMPAIGN_EVENTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_GENDER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_INTERESTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_KEYWORDS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_LANGUAGES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_LOCATIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_PLATFORMS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_PLATFORM_VERSIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| CAMPAIGN_POSTAL_CODES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| CAMPAIGN_REGIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| CAMPAIGN_SIMILAR_TO_FOLLOWERS_OF_USER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| CAMPAIGN_TV_SHOWS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_AGE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_APP_STORE_CATEGORY_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_CONVERSION_TAGS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_DEVICES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| FUNDING_INSTRUMENT_EVENTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_GENDER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_INTERESTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_LOCATIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_PLATFORMS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| FUNDING_INSTRUMENT_PLATFORM_VERSIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| FUNDING_INSTRUMENT_REGIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| LINE_ITEM_AGE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_APP_STORE_CATEGORY_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_CONVERSION_TAGS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_DEVICES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| LINE_ITEM_EVENTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_GENDER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_INTERESTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_KEYWORDS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_LANGUAGES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_LOCATIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_PLATFORMS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_PLATFORM_VERSIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| LINE_ITEM_POSTAL_CODES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| LINE_ITEM_REGIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| LINE_ITEM_SIMILAR_TO_FOLLOWERS_OF_USER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| LINE_ITEM_TV_SHOWS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_AGE_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_APP_STORE_CATEGORY_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_CONVERSION_TAGS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_DEVICES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| PROMOTED_TWEET_EVENTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_GENDER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_INTERESTS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_KEYWORDS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_LANGUAGES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_LOCATIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_PLATFORMSREPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_PLATFORM_VERSIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, PLATFORM_TARGET_VALUE |
| PROMOTED_TWEET_POSTAL_CODES_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| PROMOTED_TWEET_REGIONS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT, COUNTRY_TARGET_VALUE |
| PROMOTED_TWEET_SIMILAR_TO_FOLLOWERS_USER_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENT_NAME, PLACEMENT |
| PROMOTED_TWEET_TV_SHOWS_REPORT | ACCOUNT_ID, ENTITY_ID, DATE, SEGMENTNAME, PLACEMENT |
Data Model
The following is the list of tables that are created in the Destination for your objects and reports when you run the Pipeline:
Objects
These objects enable you to create, manage, and optimize your Twitter Ads campaigns.
-
Accounts
-
Funding Instruments
-
Campaigns
-
Line Items
-
Promoted Tweets
-
Media Creative
Reports
Hevo supports data ingestion for the following types of reports:
-
Unsegmented
-
Segmented
Unsegmented reports
These reports provide you with an overview of your Twitter Ads campaign performance.
-
Account Report
-
Campaign Report
-
Funding Instrument Report
-
Line Item Report
-
Promoted Tweet Report
-
Media Creative Report
Segmented reports
These reports provide you with a detailed view of your Twitter Ads campaign performance, segregated as per a specific criterion. For example, to know the success of a campaign based on age, you can use the CAMPAIGN_AGE_REPORT.
Read Twitter Ads API Analytics and Metrics and Segmentation to know more about segmented reports.
-
Account Age Report
-
Account App Store Category Report
-
Account Devices Report
-
Account Events Report
-
Account Gender Report
-
Account Interests Report
-
Account Locations Report
-
Account Platforms Report
-
Account Platform Versions Report
-
Account Postal Codes Report
-
Account Regions Report
-
Campaign Age Report
-
Campaign App Store Category Report
-
Campaign Conversion Tags Report
-
Campaign Devices Report
-
Campaign Events Report
-
Campaign Gender Report
-
Campaign Interests Report
-
Campaign Keywords Report
-
Campaign Languages Report
-
Campaign Locations Report
-
Campaign Platforms Report
-
Campaign Platform Versions Report
-
Campaign Postal Codes Report
-
Campaign Regions Report
-
Campaign Similar To Followers Of User Report
-
Campaign TV Shows Report
-
Funding Instrument Age Report
-
Funding Instrument App Store Category Report
-
Funding Instrument Conversion Tags Report
-
Funding Instrument Devices Report
-
Funding Instrument Events Report
-
Funding Instrument Gender Report
-
Funding Instrument Interests Report
-
Funding Instrument Locations Report
-
Funding Instrument Platforms Report
-
Funding Instrument Platform Versions Report
-
Funding Instrument Regions Report
-
Line Item Age Report
-
Line Item App Store Category Report
-
Line Item Conversion Tags Report
-
Line Item Devices Report
-
Line Item Events Report
-
Line Item Gender Report
-
Line Item Interests Report
-
Line Item Keywords Report
-
Line Item Languages Report
-
Line Item Locations Report
-
Line Item Platforms Report
-
Line Item Platform Versions Report
-
Line Item Postal Codes Report
-
Line Item Regions Report
-
Line Item Similar To Followers Of User Report
-
Line Item TV Shows Report
-
Promoted Tweet Age Report
-
Promoted Tweet App Store Category Report
-
Promoted Tweet Conversion Tags Report
-
Promoted Tweet Devices Report
-
Promoted Tweet Events Report
-
Promoted Tweet Gender Report
-
Promoted Tweet Interests Report
-
Promoted Tweet Keywords Report
-
Promoted Tweet Languages Report
-
Promoted Tweet Locations Report
-
Promoted Tweet Platforms Report
-
Promoted Tweet Platform Versions Report
-
Promoted Tweet Postal Codes Report
-
Promoted Tweet Regions Report
-
Promoted Tweet Similar To Followers User Report
-
Promoted Tweet TV Shows Report
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
From version 10 of Twitter Ads API, only advertising-enabled accounts are visible in the Ads Accounts drop-down while configuring Twitter Ads as a Source in Hevo. Any existing Pipelines created with accounts not enabled for advertising are not affected. However, if you want to continue using the non-advertiser accounts, you must enable them for advertising. Read Ads account creation for the steps to do this.
-
Twitter Ads has made the following changes to the Line Items object:
-
Renamed the
bid_typefield tobid_strategy. -
Deprecated the
automatically_select_bidandtracking_tagsfields.
As a result, from Release 1.81 onwards, Hevo:
-
automatically maps the
bid_strategyfield to the Destination table, if you had enabled Auto Mapping while creating the Pipeline. -
ingests null values for the
automatically_select_bidandtracking_tagsfields.
-
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-13-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Twitter Ads as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Sep-30-2024 | 2.28.1 | Updated section, Data Replication to change the default ingestion frequency to 12 Hrs. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-30-2023 | NA | Updated the page as per the latest Twitter Ads UI. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Feb-07-2022 | 1.81 | - Reorganized the content in the Data Replication section. - Segregated the reports content based on their type in sections, Schema and Primary Keys and Data Model. - Added section, Source Considerations. |
| Jan-03-2022 | 1.79 | Added information about reverse historical load in the Data Replication section. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |