Release Version 2.29
On This Page
The content on this site may have changed or moved since you last viewed it. As a result, some of your bookmarks may become obsolete. Therefore, we recommend accessing the latest content via the Hevo Docs website.
This release note also includes the fixes provided in all the minor releases since 2.28.
To know the complete list of features available for early adoption before these are made generally available to all customers, read our Early Access page.
In this Release
New and Changed Features
Destinations
-
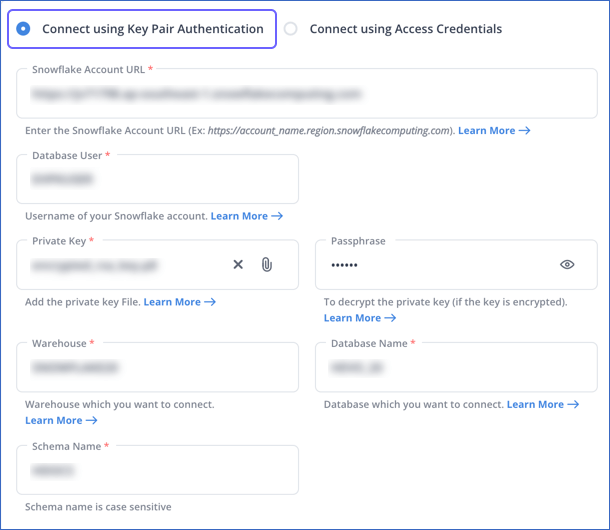
Support for Key Pair Authentication in Snowflake (Added in Release 2.28.2)
-
Hevo now supports connecting to your Snowflake data warehouse Destination using a key pair for authentication, making the connection more secure. Instead of a database password, you can now provide a private key while configuring a new Snowflake Destination or modifying an existing one.
-
Sources
-
Updated Default Ingestion Frequency for Amazon Ads, Facebook Ads, Google Ads, Microsoft Ads, and Twitter Ads (Added in Release 2.28.1)
- The default ingestion frequency for Pipelines created with the Amazon Ads, Facebook Ads, Google Ads, Microsoft Ads, and Twitter Ads Sources has been updated to 12 hours. This change helps manage resources effectively when high volumes of data are being ingested from these Sources.
Fixes and Improvements
Destinations
-
Handling Infinite Schema Refresh Attempts for All Destinations (Fixed in Release 2.28.1)
-
Fixed an issue where Hevo repeatedly triggered the schema refresh job every 15 minutes for all Destinations, leading to excessive queries and higher costs for users when the refresh job failed. Now, after 10 consecutive failures, the system will pause the schema refresh job for 24 hours before trying again.
The fix is currently implemented for teams only in the AU (Australia) region to monitor its impact. Based on the results, it will be deployed to teams across all regions in a phased manner and does not require any action from you.
-
-
Handling of Reserved Keyword Column Names in Azure Synapse Analytics Destinations (Fixed in Release 2.28.3)
- Fixed an issue where Hevo was unable to load data from tables with column names that were the same as reserved keywords in Azure Synapse Analytics. This issue occurred because these column names were mistakenly treated as keywords in the query that loaded data into the Destination, causing syntax errors. With this fix, reserved keyword column names are now enclosed in double quotes in the query, preventing them from being treated as keywords and allowing for successful data loading.
Pipelines
-
Handling of Error Messages in Pipelines (Fixed in Release 2.28.1)
- Fixed an issue where users other than the authorized user within the same team encountered an error while changing the Pipeline schedule, even though the scheduling was successful. With this fix, Hevo no longer verifies the authorized user when the Pipeline schedule is updated, eliminating unnecessary error messages.
Sources
-
Handling of Data Ingestion Issues in HelpScout Source (Fixed in Release 2.28.1)
- Fixed an issue where data ingestion was getting stuck, stopping new data from being retrieved. This issue occurred when all records on a page had the same timestamp and the page had reached its size limit, preventing the page number from incrementing. With this fix, the page number is now correctly incremented based on the page size, ensuring all records are processed.
-
Handling Data Mismatch Issues in Facebook Ads (Fixed in Release 2.28.2)
-
The following fixes were made to address the data mismatch issues in Pipelines created with the Facebook Ads Source:
-
The API call to fetch the refresher data returned incorrect data when users were in a time zone other than UTC. This issue occurred because the refresher job calculated the offset by comparing UTC with the user’s local time. As a result, data was retrieved for only one day instead of 30 days. With this fix, the refresher job now calculates the offset accurately, ensuring correct data in the Destination.
-
The API call to fetch Ads data returned incorrect results if the polling job was interrupted for any reason before retrieving all records for a specific timestamp. This issue occurred because the next poll began fetching data from a timestamp later than the one being processed at the time of interruption, resulting in some records being missed. With this fix, if a poll is interrupted, data fetching will now resume from the exact timestamp of the interrupted data, ensuring correct data in the Destination.
-
-
-
Handling Data Ingestion for Materialized Views in PostgreSQL Source (Fixed in Release 2.28.3)
-
Fixed an issue where materialized views were being ingested during incremental loads in a log-based Pipeline created with any variant of PostgreSQL, even though Hevo does not support data replication from views. This issue occurred because Hevo mistakenly identified materialized views as regular tables during incremental loads, resulting in higher data ingestion and costs.
With this fix, Hevo now checks if a table is a materialized view during incremental loads and skips it, ensuring only supported tables are ingested. This update will be deployed to teams across all regions in a phased manner and does not require any action from you. However, to enable this fix for your existing or new Pipelines, contact Hevo Support.
-
-
Handling Data Mismatch Issues in Shopify (Fixed in Release 2.28.2)
- Fixed an issue where the API call to fetch the balance_transactions object returned incorrect results. This occurred because columns containing large numbers were converted to the float data type by the system. However, as the float data type cannot accurately handle large numbers, the values were altered during the conversion process. These altered values were then reverted to their original data type before being loaded into the Destination, causing data discrepancies. With this fix, Hevo ensures that the affected columns are correctly handled by converting them to a long data type, which can accurately store large numbers.
-
Handling Data Mismatch Issues in Stripe (Fixed in Release 2.28.2)
- Fixed an issue where the API call made to fetch the Charge object returned null values for the
customer_idfield, resulting in missing data. This issue occurred because the nested Refund object did not expand the customer Event, and as a result, thecustomer_idfield was not included in the API call. With this fix, Hevo ensures that thecustomer_idfrom the Refund object is included as a parameter in the API call, ensuring that the data is loaded accurately into the Destination.
- Fixed an issue where the API call made to fetch the Charge object returned null values for the
-
Handling Incorrect Alerts for Deleted Folders in Google Drive Source (Fixed in Release 2.28.3)
-
Fixed an issue where users received incorrect alerts after deleting a folder in Google Drive. When a folder is deleted, Hevo marks the object and task statuses as finished to indicate its removal. However, the following issues occurred:
-
If the Pipeline was not updated, the statuses were not marked as finished, inaccurately indicating them as still present.
-
If the Pipeline was updated, only the object status was marked as finished, leaving the task status unchanged.
As a result, when Hevo attempted to ingest data from Google Drive later, it checked the statuses of all folders. Because the statuses of the deleted folders were not updated correctly, Hevo indicated that these folders still existed, which triggered alerts to users about missing folders. With this fix, both the object and task statuses are now accurately marked as finished when a folder is deleted, preventing incorrect alerts.
-
-
-
Handling Tasks Object Failure in Onfleet Source (Fixed in Release 2.28.1)
-
Fixed an issue where Hevo was unable to ingest data from the Tasks object due to a missing API endpoint in Onfleet’s system. With this fix, Hevo has updated the API endpoint to ensure seamless data ingestion. Additionally, pagination has been implemented to optimize the data retrieval process.
This fix applies to all new Pipelines created after Release 2.28.1 for teams only in the US and US2 (United States) regions to monitor its impact. Based on the results, it will be deployed to teams across all regions in a phased manner and does not require any action from you for new Pipelines. To enable this fix for existing Pipelines, contact Hevo Support.
-
-
Improved Handling of Fulfillment Orders Object in Shopify Source (Fixed in Release 2.28.3)
-
The following changes were made to the Shopify integration for the Fulfillment Orders object:
-
Improved Data Ingestion: The limit on the number of records ingested has been increased from 50 to 250. This change allows for more data to be ingested from the object, reducing the possibility of missed records.
-
Addressed Data Mismatch Issue: The
fulfillment_holdsfield was omitted while parsing the API response for the Fulfillment Orders object, causing the API to fetch incomplete data. To fix this issue, Hevo now includes the field during parsing, ensuring that all data from the object is fetched.This fix applies to Pipelines created with Shopify as a Source after Release 2.28.3. If you observe a data mismatch for the Fulfillment Orders object in your existing Pipelines, you must create a new Pipeline.
-
-
-
Improved Offset Management in Klaviyo v2 Source (Fixed in Release 2.28.3)
- Fixed an issue in the Klaviyo v2 integration where the API call to fetch the Events_v2 object returned incomplete data. The polling job used the timestamp of the last record retrieved as the offset for the next poll. However, the records were not sorted by timestamp, and the next poll fetched data from a timestamp later than the offset. As a result, data between the previous and new offsets was not ingested. With this fix, Hevo now sorts the records by their timestamps, ensuring that all data is fetched in the correct order and preventing data loss.
Documentation Updates
The following pages have been created, enhanced, or removed in Release 2.29:
Activate
-
Activate Concepts