Release Version 1.99
On This Page
The content on this site may have changed or moved since you last viewed it. As a result, some of your bookmarks may become obsolete. Therefore, we recommend accessing the latest content via the Hevo Docs website.
In this Release
New and Changed Features
Account Management
-
Cool-off Period for New Accounts
- Introduced a 30-day cool-off period for customers signing up after Release 1.99, to allow them to comprehensively explore Hevo without the hassle of maintaining multiple teams, workspaces, and pricing plans. During the cool-off period, you can create one workspace post-start of the free product trial. Once this period ends, you can create the next workspace with the same cool-off period, and similarly, create up to five workspaces for your domain.
Pipelines
-
Event Usage Management
-
Provided the Data Spike Alert feature that allows you to set a daily limit on the number of Events loaded by a Pipeline and be alerted whenever this threshold is exceeded. In addition, you can opt to pause the Pipeline at such time. This allows you to control the Events usage and be alerted to any anomalies in the replication process.
This feature is applicable to all new and existing Pipelines. However, the option of pausing the Pipeline when the threshold is exceeded is not available for log-based Pipelines. This is because pausing the Pipeline may cause the logs to expire, which might lead to loss of data.

Read Data Spike Alerts.
-
-
Optimize Query Mode Post-Pipeline Creation
-
Introduced a feature that alerts you whenever the Full Load Objects in your Pipeline account for more than 10% of the billable Events count. You can optimize the usage costs by selecting a more suitable query mode at this time. The feature also provides the option to modify the query mode for each object individually or do a bulk change for multiple objects. This feature is currently available for RDBMS Sources such as MySQL, PostgreSQL, and MS SQL.

-
Sources
-
Ingestion of New Objects in Salesforce
-
Enhanced the integration to support the ingestion of any new object created in the Source post-Pipeline creation. For this, you can enable the Include New Objects in the Pipeline option while creating the Pipeline or post-creation of the Pipeline. Any object created in the Source subsequent to enabling this option is automatically considered for ingestion.

-
-
Pipedrive as a Source
-
Provided integration with Pipedrive as a Source for creating Pipelines.

Read Pipedrive.
-
-
Quicker Access to Historical Data for Front
- Implemented historical load parallelization for new Pipelines. Hevo now divides the historical data into multiple parts and then ingests these parts simultaneously. This enables you to access your historical data faster.
-
Support for Additional Objects in Shopify
-
Added support for ingesting data for 17 additional objects. This feature is applicable to all new Pipelines.
Read Data Model.
-
-
Support for Additional Objects in Mailchimp
-
Added support for ingesting data for three additional objects: Click Reports, Click Reports Members, and Email Activity Reports for the Wining Variate campaign type. This feature is applicable to all new Pipelines.
Read Data Model.
-
-
Support for Ingesting Compressed Files in Amazon S3
-
Enhanced the integration to support the ingestion of tar.gz and zip compressed files containing the supported file formats. This feature is applicable to all new Pipelines.
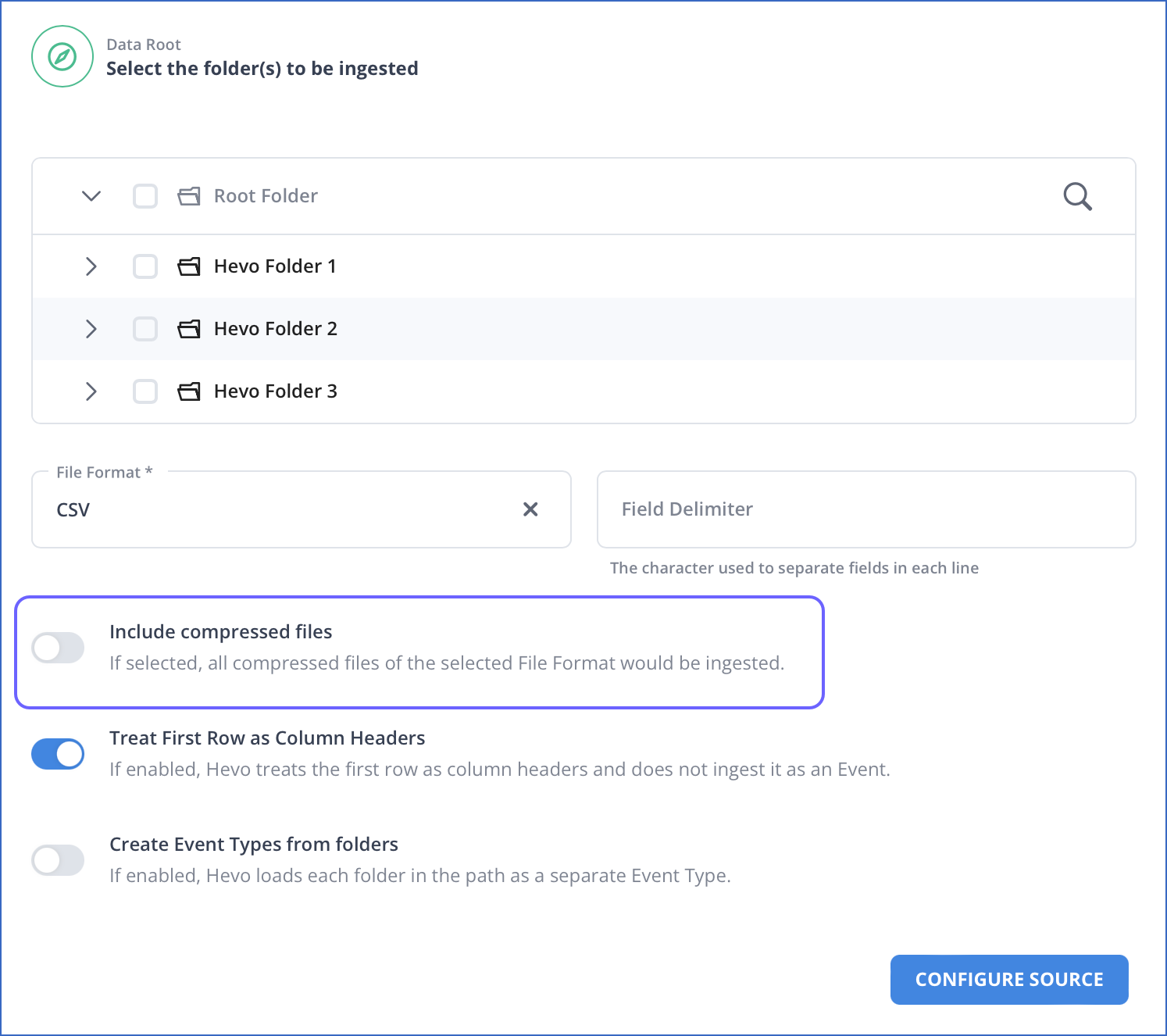
-
-
Support for Updates and Deletes for Additional Stripe Objects
-
Enhanced the integration to support updates and deletes for 15 additional Stripe objects.
-
User Experience
-
Easier Database Selection in MySQL Source Configuration
-
Provided the option to select specific databases while configuring MySQL as a Source. Hevo fetches the databases in your MySQL account and displays them for selection. Therefore, now you do not need to enter the names of the specific MySQL databases to be replicated.

-
-
Easier Query Mode Selection for Objects in JDBC Sources
-
Enhanced the Hevo functionality to suggest the optimal query mode for all the JDBC Source objects, in case of Pipelines created in Table mode. The Configure Objects page displays the optimal query mode for each object and allows you to select the appropriate column for that query mode. This feature is available for all new Pipelines.
Read Pipeline Objects.
-
-
Initial Setup Assistance for Warehouse Destinations
-
Enhanced the Amazon Redshift, Google BigQuery, and Snowflake Destination documentation to help users with the initial setup steps, such as creating an account, setting up an instance, and creating the database.
Read Amazon Redshift, Google BigQuery, and Snowflake.
-
Fixes and Improvements
Destinations
-
Faster Loading of Data to Google BigQuery using AVRO Files
- Enhanced the integration to write the ingested data to AVRO files, instead of the previously used JSON format, and use these files to load the data into the Destination. This ensures faster loading of data into your Google BigQuery Destination. This feature is applicable for all new and existing Pipelines.
Pipelines
-
Ingestion of New Tables Post-Pipeline Creation for JDBC Sources
- Fixed an issue in JDBC Source Pipelines created using Hevo API, whereby the new tables in the Source were being ingested even if the Include New Tables option was disabled while creating the Pipeline.
Sources
-
Data Ingestion Deferment in Amazon DynamoDB Pipelines
- Enhanced the Amazon DynamoDB integration to defer the incremental data ingestion to a pre-determined time if you are using DynamoDB Streams for your Pipeline and Hevo does not have the required permissions on any of the objects. This is an improvement over the earlier behavior in which no deferment of ingestion occurred and the errors were shown for every object. This change is applicable to all new and existing Pipelines.
Documentation Updates
The following pages have been created, enhanced, or removed in Release 1.99:
Alerts
Data Ingestion
Data Loading
- Data Spike Alerts (New)
Destinations
Getting Started
Models
- Models FAQs (New)
Pipelines
Sources
-
Amazon S3 FAQs (New)
-
Google Sheets FAQs (New)
-
Pipedrive (New)
-
PagerDuty (New)