Release Version 2.14
On This Page
The content on this site may have changed or moved since you last viewed it. As a result, some of your bookmarks may become obsolete. Therefore, we recommend accessing the latest content via the Hevo Docs website.
To know the list of features and integrations we are working on next, read our Upcoming Features page!
In this Release
New and Changed Features
Sources
-
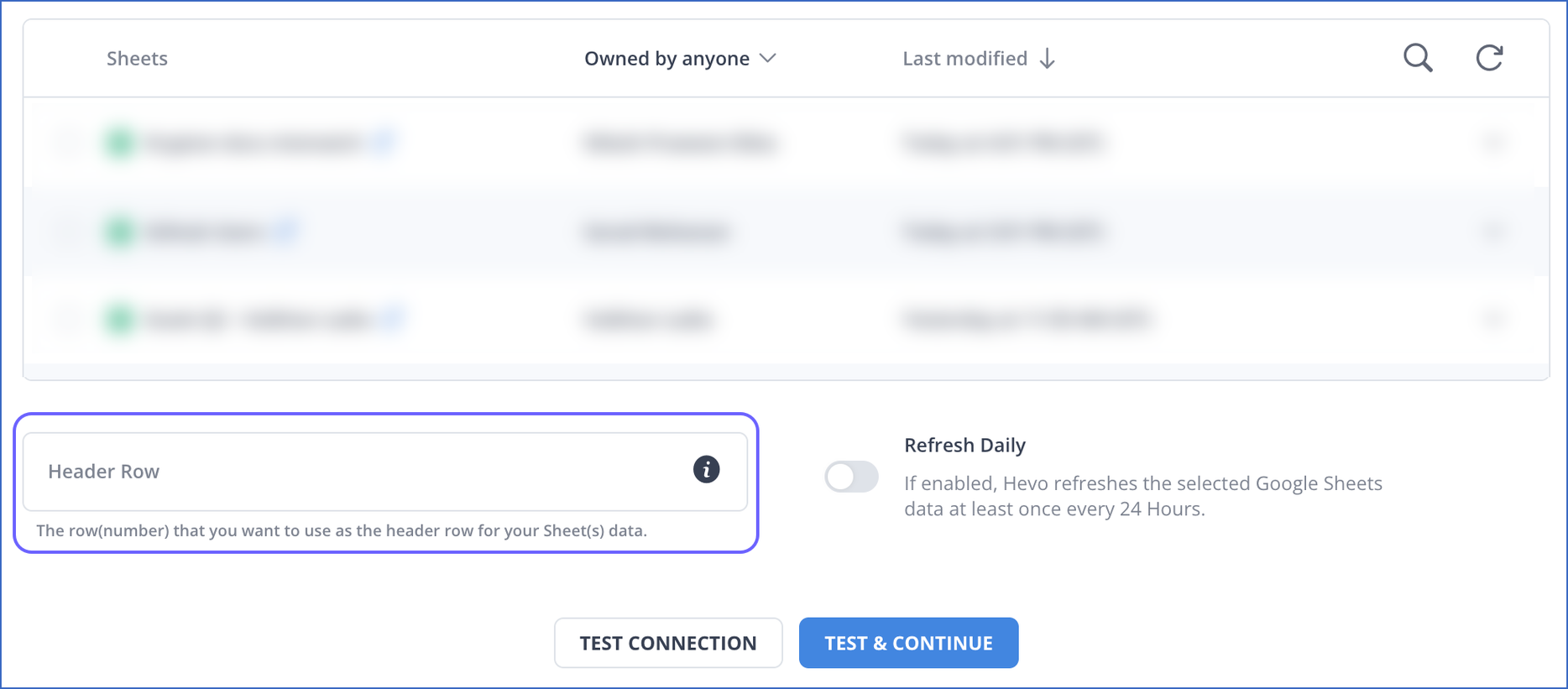
Support for Custom Headers in Google Sheets
-
Enhanced the integration to allow you to use any row from a sheet as the header row. This is an improvement over the earlier behavior in which the first row was used as a header. This change is applicable to all new and existing Pipelines. However, for existing Pipelines, you must modify the Source configuration to specify this field.
-
-
Support for Versioned APIs in LinkedIn Ads
-
Enhanced the integration to use versioned APIs for fetching data from your LinkedIn Ads account. This change applies to all Pipelines created after June 19, 2023. If you have existing Pipelines and want to use the versioned API, you must create a new Pipeline. Effective June 30, 2023, LinkedIn Ads will no longer support their unversioned APIs.
Read Schema and Primary Keys and Data Model.
-
User Experience
-
Removed Support for Google Campaign Manager as a Source
- From Release Version 2.14, Hevo has stopped supporting Google Campaign Manager (GCM) as a Source. As a result, you will not be able to create Pipelines for this Source. Further, any existing Pipelines will stop processing data.
Fixes and Improvements
Sources
-
Faster Historical Data Ingestion for Log-based Pipelines
- Extended the functionality to ingest data in parallel from objects skipped at Pipeline creation. Hevo divides the data for these objects into smaller parts and fetches data from them at the same time. This change reduces the time taken to ingest large amounts of data. The feature applies to all new and existing log-based Pipelines
-
Simultaneous Ingestion of Historical and Incremental Data for SQL Server Sources
- Introduced simultaneous ingestion of historical and incremental data in Pipelines created with SQL Server Sources having Change Tracking as the ingestion mode. This method ensures faster replication of data to your Destination.
-
Improved Historical Load Parallelization for Table Mode Pipelines
- Implemented historical load parallelization for Pipelines created with Table mode for relational database Sources. Hevo now divides the historical data into multiple parts and then ingests these parts simultaneously. This method provides you with faster access to your historical data.
User Experience
-
Automatic Query Mode Selection for PostgreSQL Source
-
Enhanced the integration to set the query mode to XMIN in Table mode-based Pipelines created for all variants of the PostgreSQL Source. Now, you do not need to specify the query mode for each object while configuring your Pipeline, thus simplifying the setup process. This feature is available from Release 2.14.

Read XMIN.
-
Documentation Updates
The following pages have been created, enhanced, or removed in Release 2.14:
Account Management
Data Ingestion
Destinations
Pipelines
-
Pipeline FAQs
-
Utils
Sources
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Aug-10-2023 | NA | Added section, User Experience to inform about delisting Google Campaign Manager as a Source. |