Release Version 2.03
On This Page
The content on this site may have changed or moved since you last viewed it. As a result, some of your bookmarks may become obsolete. Therefore, we recommend accessing the latest content via the Hevo Docs website.
To know the list of features and integrations we are working on next, read our Upcoming Features page!
In this Release
New and Changed Features
Pipelines
-
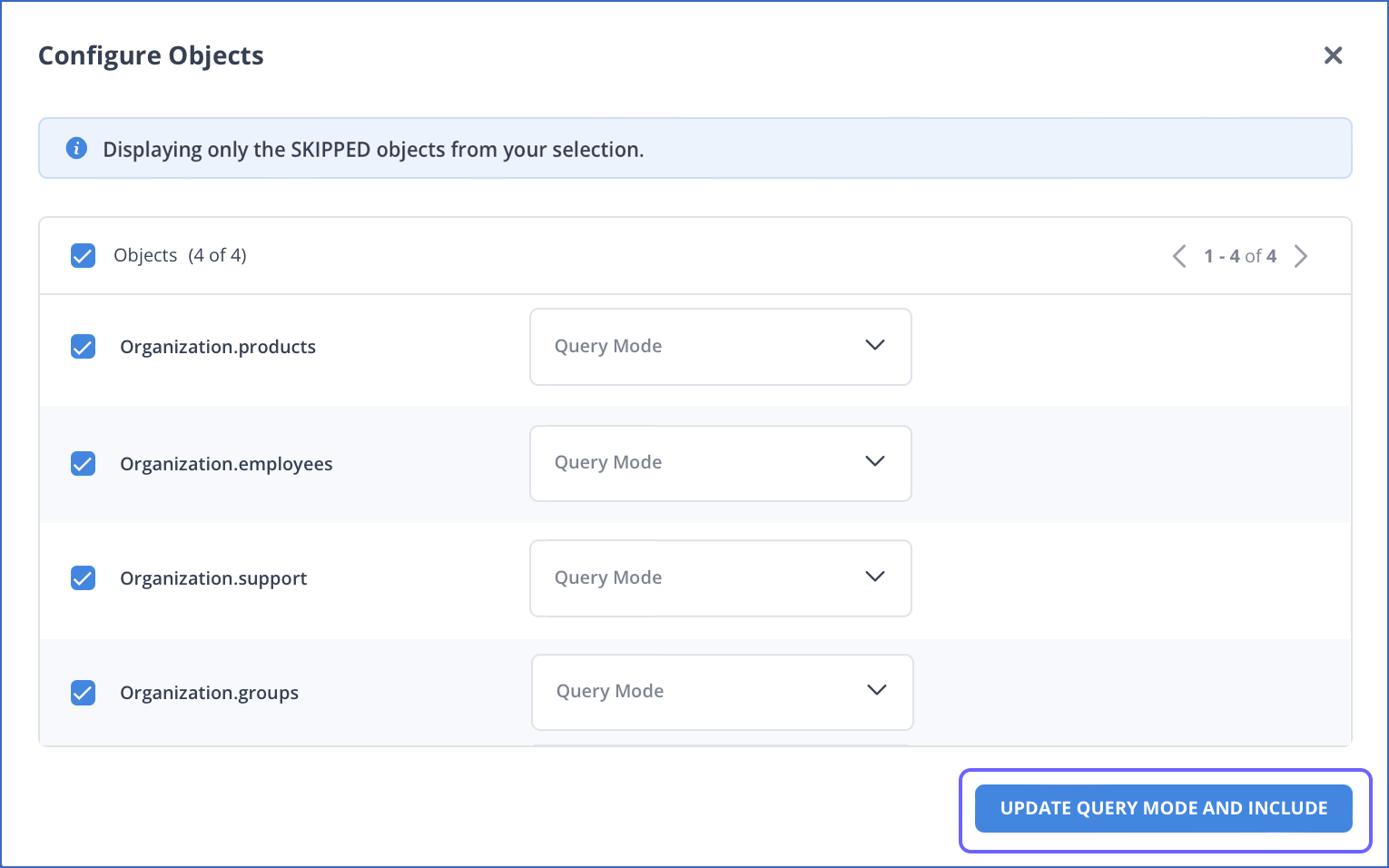
Ingestion of Skipped Objects Post-Pipeline Creation
-
Introduced the option to select the query modes while including any skipped objects post-Pipeline creation. You can also use bulk actions to include multiple objects at once and specify the query modes for them.
This feature is currently available in new and existing Pipelines with Amazon Redshift and all variants of MySQL, Oracle, PostgreSQL, or SQL Server as the Source.
-
Sources
-
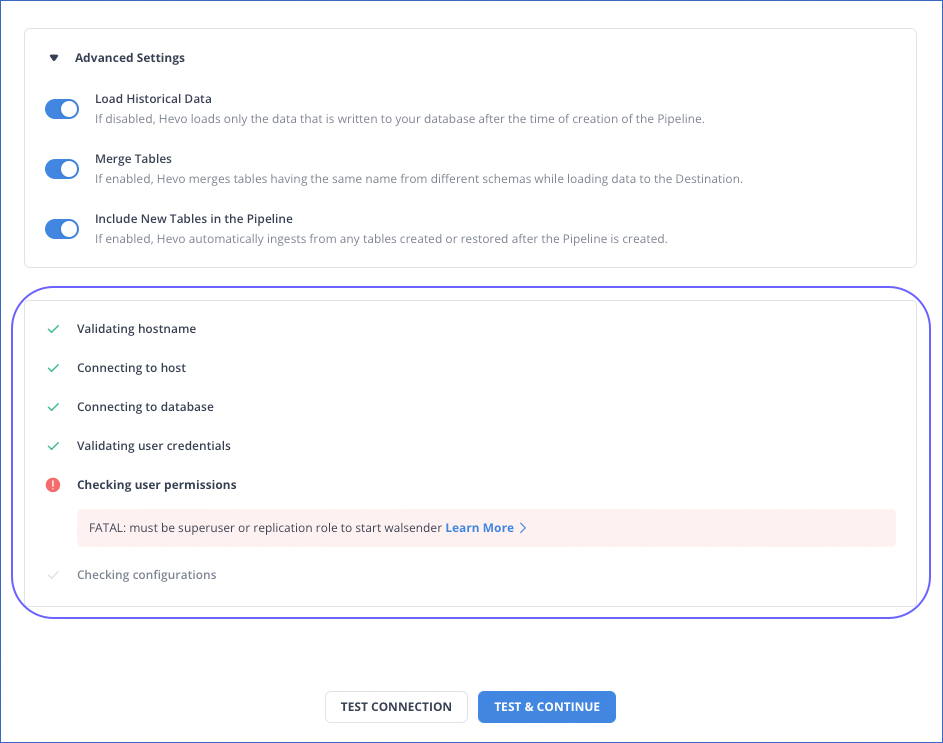
Connectivity Check for Database and Data Warehouse Sources
-
Enhanced the Hevo UI to display a connectivity check in the Source configuration page for Amazon Redshift and all variants of MongoDB, MySQL, Oracle, PostgreSQL, and SQL Server Sources to provide insight into any error encountered while connecting to the Source during and post-Pipeline creation. In case of a Source connection failure, the checker validates each Source configuration step and displays the error for the specific setting that failed, along with the suggested actions.
-
-
Faster Historical Data Ingestion for JDBC Sources
- Improved the historical load parallelization to increase the number of ingestion tasks that can run simultaneously, thereby reducing the time taken for ingesting large amounts of data.
-
Mailshake as a Source
-
Integrated Mailshake, a sales engagement platform that allows you to manage and track your leads. To use this integration, you must generate the API keys in the Mailshake account from where you want to ingest the data. The API keys are used for authentication by Hevo to access the data.

Read Mailshake.
-
-
Slack as a Source
-
Integrated Slack, a messaging platform, as a Source for creating Pipelines.
To use this integration, you must create an app and generate the OAuth token in the Slack workspace from where you want to ingest the data. You must specify this token while configuring the Source, to authenticate Hevo for accessing your data.

Read Slack.
-
-
Support for Additional Objects in Swell
-
Added support for ingesting data for 11 additional objects. This feature is applicable to all new Pipelines.
Read Data Model.
-
-
Support for Service Accounts in Google BigQuery Source
-
Enhanced the BigQuery Source integration to allow authentication using service accounts. This feature is available for new Pipelines.

-
User Experience
-
Initial Setup Assistance for the SQL Server Destination
-
Enhanced the SQL Server Destination documentation to help users with the initial setup steps, such as setting up an instance, creating an SQL login, and creating the database.
Read Microsoft SQL Server.
-
Fixes and Improvements
Performance
-
Faster Data Loading for Snowflake Destinations
-
Improved the data loading process to optimize the load latency and reduce computing costs by:
-
Storing the data to be loaded in CSV files instead of JSON files, as loading data from CSV files is faster.
-
Providing the location of the data files in Amazon S3 buckets to Snowflake using an external stage, granting Snowflake direct but temporary access to the data to be loaded. As a result, Hevo no longer needs to copy the data into a table with a VARIANT data type column before copying it to the staging table for processing.
-
-
-
Faster Ingestion through better Handling of TOASTed Data in PostgreSQL
- Enhanced the data ingestion process to avoid delays while reading TOASTed (compressed) data from the Source. Hevo now processes the TOASTed Events independent of the other Events instead of processing all the data sequentially, to avoid delays while reading the TOASTed data. This feature is applicable for all new and existing Pipelines.
-
Optimized Data Ingestion for NetSuite ERP
- Reduced instances of the INVALID_SEARCH_MORE error while making API requests. Hevo now defers the ingestion of the objects for which this error is displayed. For Full Load objects, the ingestion is deferred for 12 hours, and for incremental objects, it is deferred for 30 minutes. This feature is applicable for all new and existing Pipelines.
Documentation Updates
The following pages have been created, enhanced, or removed in Release 2.03:
Introduction
Destinations
-
Troubleshooting Amazon Redshift Destination
Pipelines
-
Pipeline FAQs
- Can I have the same Source and Destination in the Pipeline? (Deleted)
-
Drag and Drop Transformations